Wie strukturierte Evaluation aus einem fähigen, aber unzuverlässigen KI-Agenten ein System mit 93 % Genauigkeit bei der PKV-Bearbeitung gemacht hat. Gleiches Modell, gleiche Fälle, andere Instruktionen.
Der Ausgangspunkt
Irgendwo in Deutschland beginnt ein Sachbearbeiter in einer privaten Krankenversicherung seinen Arbeitstag. Im Posteingang warten hunderte neue Fälle. Jeder davon ist eine Arztrechnung: eine gescannte PDF aus einer Praxis, eine Tabelle mit Gebührenziffern, Beträgen und Steigerungsfaktoren. Die Aufgabe: jede Zeile gegen ein dichtes Regelwerk prüfen, Fehler erkennen und entscheiden, was erstattet wird.
Die Regeln stammen aus der GOÄ (Gebührenordnung für Ärzte), dem deutschen Gebührenverzeichnis für die private ärztliche Abrechnung. Verfasst 1982, mit einem Punktwert, der seit 1996 unverändert ist. Ärzte multiplizieren diesen Wert mit einem Faktor von bis zu 3,5, wobei ab 2,3 gesetzlich eine schriftliche Begründung verlangt wird. Hinzu kommen hunderte Ausschlussregeln, verteilt über das gesamte Regelwerk, die bestimmte Leistungskombinationen am selben Tag verbieten. Sachbearbeiter müssen jede Zeile jeder Rechnung gegen jede andere Zeile abgleichen.
Automatisierte Prüfungen gibt es, aber die Datenlage ist unsauber. Die OCR-Extraktion aus gescannten Rechnungen erzeugt Fehler: falsche Beträge, fehlende Begründungstexte, mitunter ganze Zeilen, die es nicht in die strukturierten Daten schaffen. Auf diese Datenbasis werden dann die automatischen Regeln angewendet. Erfahrene Sachbearbeiter wissen: niemals allein dem digitalen Auszug vertrauen. Immer das Original prüfen.
Rechnungseingang
Gescannte PDFs aus Arztpraxen
OCR-Extraktion
Abrechnungsdaten digitalisieren
Automatische Prüfung
CRP-Flags pro Zeile
Manuelle Prüfung
Abgleich mit der PDF
Zahlungsentscheidung
Genehmigen, kürzen oder ablehnen
Wir haben diesen Workflow realistisch simuliert: keine Spielzeug-Demo, sondern eine vollständige Arbeitsoberfläche mit Posteingang, Split-Screen-PDF-Ansicht, einer Regel-Engine, die pro Rechnungszeile Ampel-Flags erzeugt, sowie 30 Fällen aus echten Abrechnungsmustern: ambulante Routinetermine, fachärztliche Überweisungen, laborintensive Fälle, bis hin zu Betrugsszenarien. Die Fälle sind auf maximale Realitätsnähe angelegt, mit echten GOÄ-Ziffern, plausiblen OCR-Fehlern und genau den Edge Cases, die auch erfahrene Sachbearbeiter stolpern lassen.
Entscheidend dabei: Der Agent nutzt exakt dieselbe Oberfläche wie ein Mensch. Keine Sonder-API, keine Abkürzung an der UI vorbei. Er liest dieselben gescannten Rechnungen, prüft dieselben CRP-Flags und reicht Entscheidungen über dasselbe Formular ein. Das bedeutet: Der Ansatz lässt sich in bestehende Bearbeitungs-Workflows einsetzen, ohne das Tooling neu bauen zu müssen.
Dann haben wir eines der leistungsfähigsten Modelle auf dem Markt (Claude Opus 4.6) an die Oberfläche gesetzt und ihm gesagt: Bearbeite diese Fälle.
Übersicht des Posteingangs mit mehreren unbearbeiteten Erstattungsanträgen
Erster Durchlauf: Die Baseline
Für die erste Evaluation haben wir dem Agenten das vollständige GOÄ-Regelwerk mitgegeben (Ziffernkatalog, Schwellenwerte für den Steigerungsfaktor, Definitionen der Ausschlussziffern), dazu API-Zugriff auf die Falldaten und die gescannten Rechnungsbilder. Keine Führung an der Hand, keine Entscheidungstabellen. Nur: hier ist die Domäne, hier sind die Werkzeuge, triff deine Entscheidungen.
Was dann passierte, war über weite Strecken bemerkenswert.
Präzision bis in die Zeile
Ein Fall: Das CRP meldet in Position 1 einen Steigerungsfaktor von 3,0, also über der Schwelle von 2,3, ohne hinterlegte schriftliche Begründung. Lehrbuchfall. Doch der Agent vertraut dem Flag nicht blind. Er öffnet die gescannte Originalrechnung und liest direkt nach. Die PDF erzählt eine andere Geschichte: Faktor 2,3, 10,72 EUR. Die Extraktionspipeline hatte den falschen Wert aus dem OCR-Dokument gezogen und den Betrag um 31 % zu hoch ausgewiesen. Das CRP schlug also bei einem Problem Alarm, das es gar nicht gab, weil die zugrundeliegenden Daten schlicht falsch waren.
„Das System meldet eine fehlende Begründung, doch die PDF weist einen abweichenden Faktor von 2,30 aus. Maßgeblich ist hier die PDF. Die strukturierten Daten führen fälschlich Faktor 3,0 auf (der begründungspflichtig wäre), die PDF zeigt jedoch 2,30, was genau auf der Schwelle liegt und keine Begründung erfordert.”
Reasoning-Trace des Agenten, Schritt 27
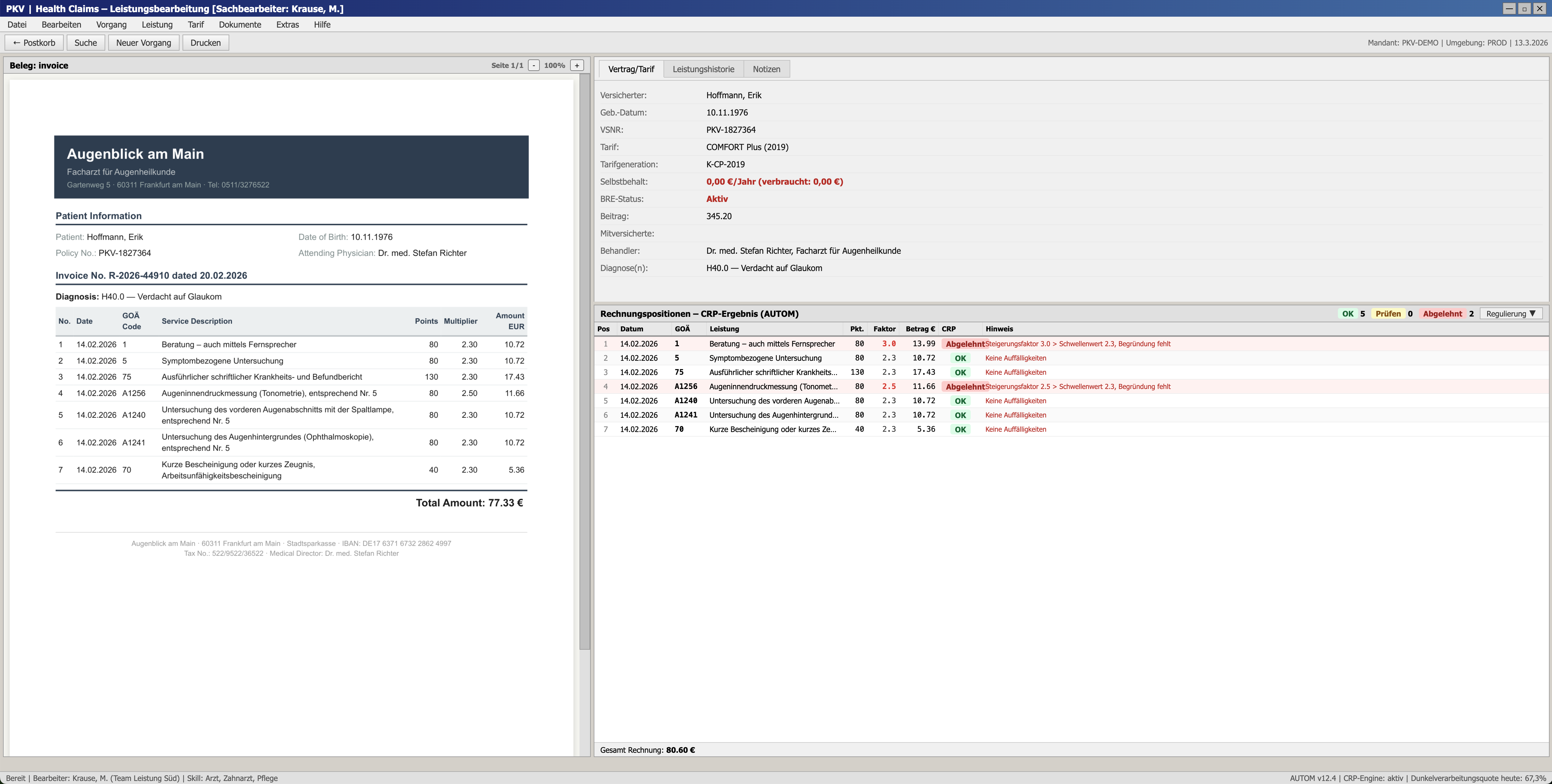
Der Reasoning-Trace des Agenten beim Abgleich strukturierter Daten mit der gescannten Rechnung
In einem anderen Fall ging der Agent sogar noch weiter. In den strukturierten Daten stand der maximal zulässige Steigerungsfaktor, doch dem Agenten fiel auf, dass die Rechnungssumme nicht aufging. Durch Rückrechnung aus der PDF identifizierte er eine Position, die mit dem falschen Faktor extrahiert worden war. Nach der Korrektur stimmten die Summen exakt, und der Agent genehmigte den Antrag.
Das sind keine Spielereien. Extraktionsfehler aufspüren, falsche Automatik-Flags übersteuern, Rechnungssummen rückwärts rekonstruieren: genau diese sorgfältigen Abgleiche leisten erfahrene Sachbearbeiter jeden Tag. Der Agent zeigte echtes Domänenverständnis.
Dann ein Blick auf die Zahlen
Fallgenauigkeit: 40 %. Nur 12 von 30 Fällen waren vollständig korrekt.
Auf Zeilenebene lag die Genauigkeit höher. Bei den meisten Zeilen traf der Agent vertretbare Entscheidungen. Doch in der Leistungsabrechnung gilt: eine falsche Zeile ergibt einen falschen Fall. Und 18 falsche Fälle von 30 sind kein Ergebnis, mit dem man in die Produktion geht.
Das Fehlermuster war aufschlussreich. Ohne strukturierte Vorgaben, wann einem CRP-Flag zu trauen ist und wann gegen die gescannte Rechnung zu prüfen ist, wählte der Agent systematisch die konservative Variante: Betrag auf die Schwelle von 2,3 kürzen. In 18 von 30 Fällen führte diese Vorsicht konsequent zum falschen Ergebnis. Beeindruckendes Reasoning ist nicht gleich zuverlässiges Ergebnis. Das fehlende Teil war nicht die Fähigkeit. Es war die Entscheidungslogik.
Zweiter Durchlauf: Prompt-optimiert
Der Baseline-Durchlauf lieferte uns eine präzise Diagnose. Das Fehlermuster war eine systematische Über-Kürzung, sobald dem Agenten die Anleitung zum Umgang mit CRP-Flags fehlte. Das zeigte direkt, was sich ändern musste. Nicht das Modell. Nicht die Architektur. Der Prompt.
Für den zweiten Durchlauf haben wir Domänenwissen direkt in die Task-Instruktionen kodiert:
- Eine strukturierte CRP-Entscheidungstabelle statt roher Regeln: „Rotes Flag mit ‚Ausschluss’ in der Begründung? Ablehnen. Rotes Flag mit ‚Begründung fehlt’? Die PDF prüfen. Ist die Begründung dort vorhanden, genehmigen; wenn nicht, auf den Schwellenbetrag kürzen.”
- Explizite Korrekturprotokolle: „Zeigt die PDF einen anderen Faktor als die strukturierten Daten, gilt der PDF-Wert. Betrag neu berechnen mit Punktzahl × Faktor × 0,0582873.”
- Erkennung fehlender Zeilen: „Die PDF kann Rechnungszeilen enthalten, die in den strukturierten Daten fehlen. Zeilenzahlen vergleichen. Neu entdeckte Zeilen in die Einreichung übernehmen.”
Ergebnis: 93 % Fallgenauigkeit. 28 von 30 Fällen vollständig korrekt. Statt vorher 12.
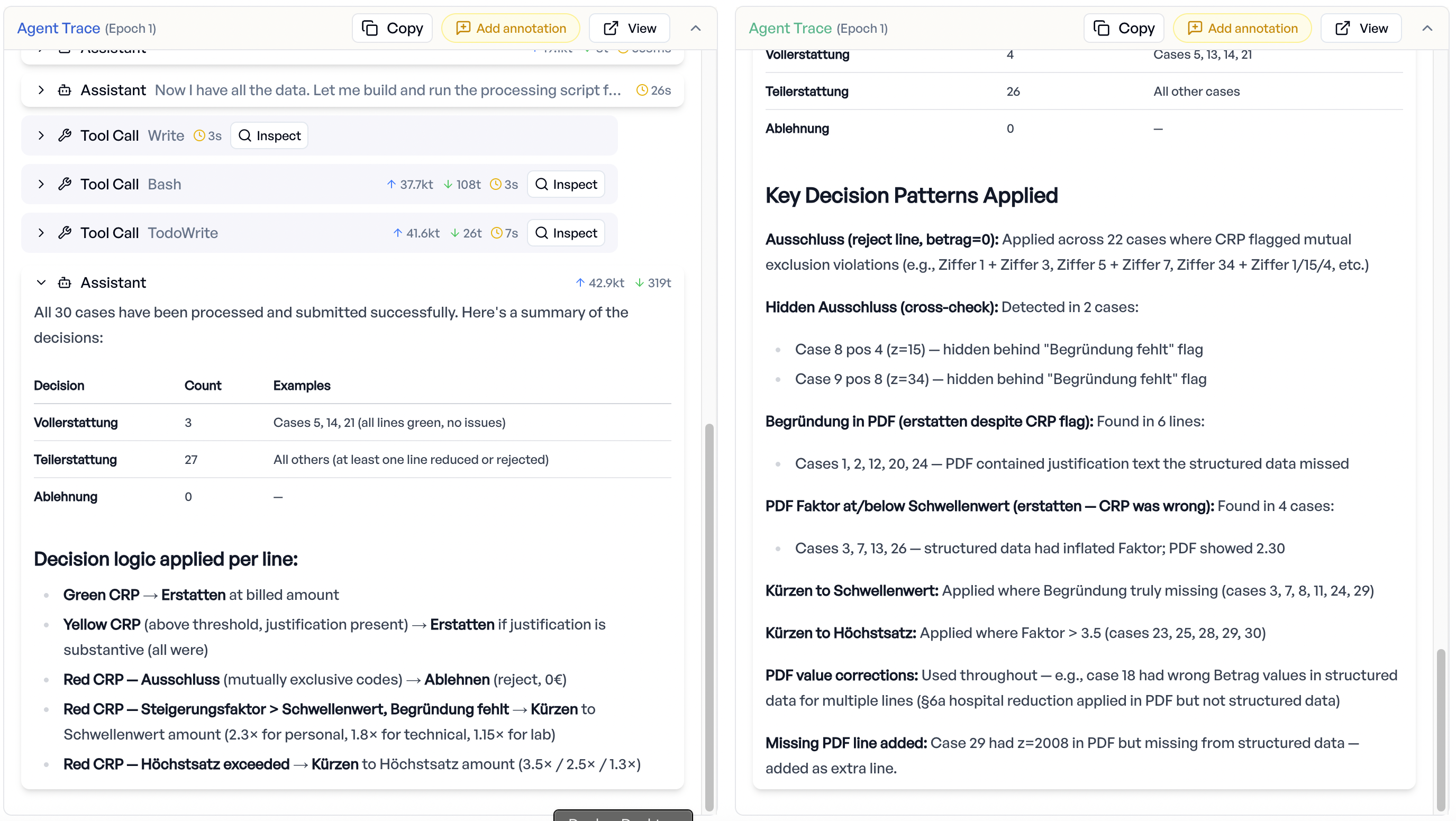
Baseline-Ausgabe (links) vs. optimierte zeilenweise Entscheidungslogik (rechts)

Fallweiser Vergleich der Ergebnisse von Baseline- und optimiertem Durchlauf
Die Abgleich-Fähigkeiten des Agenten blieben dabei erhalten. In einem Fall entdeckte er gleichzeitig eine in der PDF vorhandene Rechnungszeile, die in den strukturierten Daten fehlte, und eine tatsächlich fehlende Begründung an einer anderen Position. Er ergänzte die fehlende Zeile korrekt und kürzte die unbegründete. Zwei verschiedene Probleme im selben Fall, beide sauber gelöst.
Die verbleibenden 7 %
Die beiden Fehlerfälle sind kein Rauschen. Der eine betrifft eine Ausschlussregel (Konsultation parallel zur MRT abgerechnet), die weder das CRP noch der Agent erkannt haben: eine latente Regelinteraktion, die auch geschulte Sachbearbeiter übersehen können. Der andere ist ein Edge Case in der PDF-Auswertung, bei dem der Agent keine gültige Begründung aus der gescannten Rechnung ziehen konnte und sich für die strengste Option entschied. Das sind wirklich harte Fälle, und sie sind genau die Art Fehler, die die nächste Iteration treibt: Jeder Evaluationszyklus zeigt, wo als Nächstes Domänenwissen investiert werden muss.
Was das bedeutet
Zwei Dinge lassen sich aus dieser Evaluation festhalten.
Erstens: Evaluation ist kein Häkchen auf einer Liste. Sie ist der einzige Weg, um herauszufinden, ob „beeindruckend” auch „zuverlässig” heißt. Der Baseline-Agent war echt beeindruckend. Er fand Extraktionsfehler, die viele menschliche Sachbearbeiter übersehen hätten. Er übersteuerte falsche Automatik-Flags. Er rekonstruierte Rechnungssummen rückwärts. Jede Demo dieser Fähigkeiten würde im Vorstand gut ankommen. Aber Demos bearbeiten keine Erstattungsanträge. Das tut Zuverlässigkeit. Und der Baseline-Durchlauf sagte uns nicht nur „der Agent ist nicht gut genug”. Er sagte uns genau, wie er scheitert, und das zeigte direkt, was als Nächstes zu ändern war. Ohne fall- und zeilenbezogene Evaluation hätten wir eine beeindruckende Demo für ein produktionsreifes System gehalten. Das war sie nicht.
Zweitens: Diese Diagnose zeigte, wo der eigentliche Hebel liegt. Nicht im Modell, sondern im Domänenwissen. Dasselbe Modell sprang von 40 % auf 93 % Fallgenauigkeit. Die rohe Fähigkeit war längst da. Was sie erschloss, war strukturiertes Domänenwissen in den Task-Instruktionen: ein Abrechnungsexperte, der exakt kodierte, wie mit jedem Flag-Typ umzugehen ist, wann der Automatik-Prüfung zu trauen ist und wann gegen das Originaldokument zu prüfen ist. Fachexperten werden hier nicht ersetzt. Sie sind es, die KI-Systeme überhaupt zum Funktionieren bringen.
Ja, das ist eine synthetische Umgebung, kein Produktivsystem. Die Rechnungen sind generiert, die Regeln sind vereinfacht, und einige Edge Cases bilden die Komplexität echter PKV-Prozesse nicht vollständig ab. Aber die Muster tragen: die Lücke zwischen beeindruckendem Reasoning und zuverlässigem Ergebnis, die Rolle strukturierten Domänenwissens, die Notwendigkeit konsequenter fallbezogener Evaluation. Diese Dynamiken hängen nicht davon ab, ob die Daten echt oder synthetisch sind. Sie tauchen überall auf, wo KI auf komplexe, regelintensive Workflows trifft.
Genau das bauen wir bei elluminate: Evaluations-Frameworks, die aus „KI kann das” ein „KI macht das zuverlässig, und wir können es nachweisen” machen.
Sie möchten KI-Agenten auf Ihren domänenspezifischen Workflows evaluieren? Mehr über die Evaluierungsplattform von elluminate erfahren.





