Wer Langfuse oder andere Observability-Plattformen nutzt, um LLM-Anwendungen zu überwachen, hat in der Regel hunderte echter Interaktionen gesammelt: Konversationen, Edge Cases und Fehlerfälle, die sich perfekt als Testfälle eignen würden. Nur: Diese Daten in den Evaluations-Workflow zu bekommen, bedeutet meist Exportskripte, CSV-Gefummel und manuelle Aufbereitung.
elluminate importiert Langfuse-Datensätze jetzt direkt.

Observability trifft Evaluation
Die Stärken von Langfuse liegen in Observability, Tracing und Monitoring produktiver Systeme. elluminate will das nicht ersetzen, sondern ergänzt eine strukturierte Evaluationsebene.
Die Stärke von elluminate ist die systematische Evaluation: Experimente nachverfolgen, Batch-Tests fahren, Prompts wiederholbar vergleichen - und das alles einfach in der Handhabung.
Zusammen entsteht ein geschlossener Kreislauf von Produktionsproblemen zu messbaren Verbesserungen:
- Schwache Ausgaben in der Produktion erfassen
- In einen Langfuse-Datensatz übernehmen
- In elluminate importieren
- An Prompts, Kriterien und Modellen iterieren
- Klare Kennzahlen gewinnen, Verbesserungen messen und Änderungen zuverlässig ausrollen
Ihre Produktionsdaten treiben Ihre Evaluation, Ihre Evaluation verbessert die Produktion.
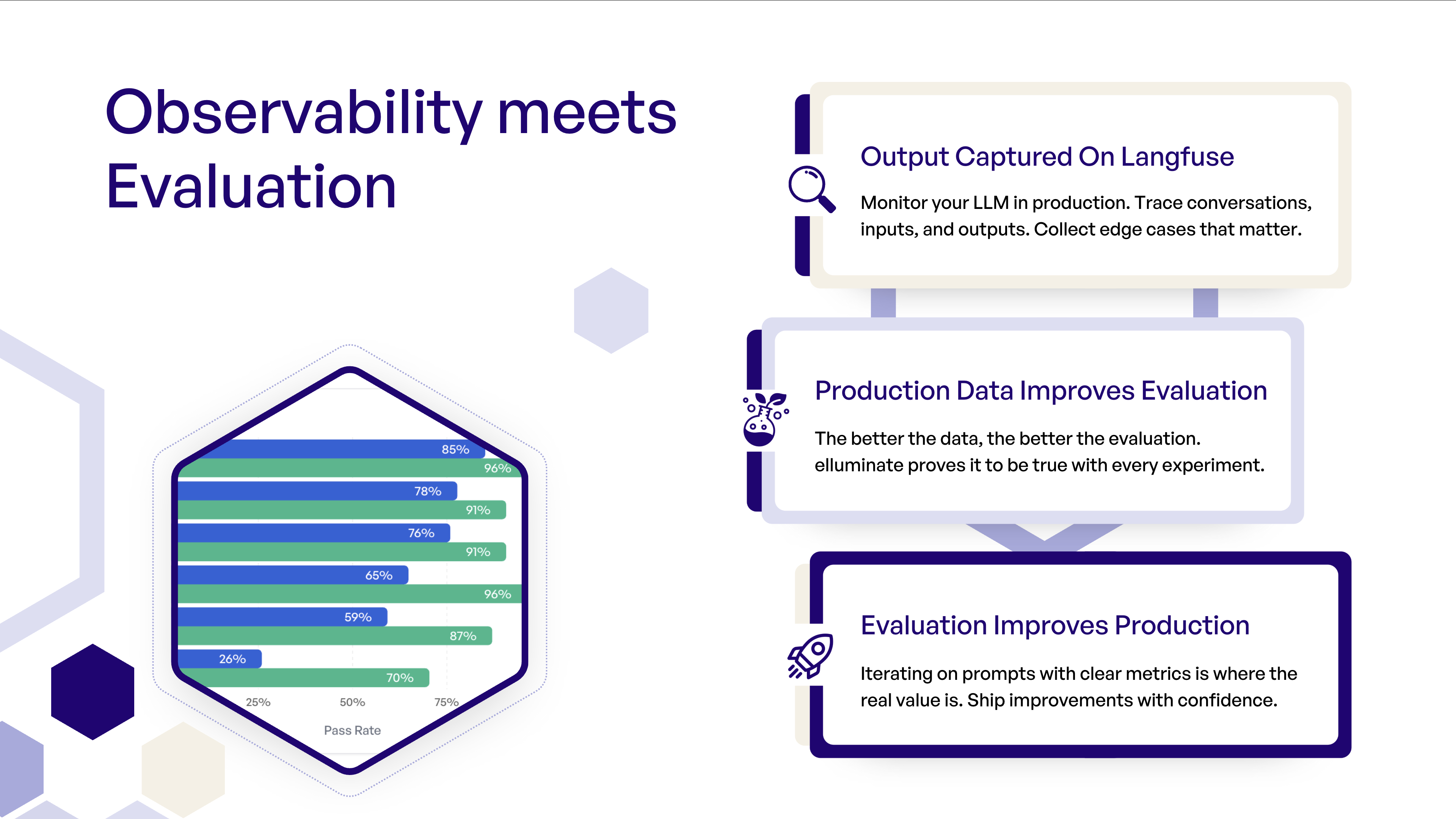
Beispiel: Von Produktionsproblemen zur systematischen Verbesserung
Autor: Dominik Römer, AI Engineer bei ellamind
Anwendungsfall: Ein Q&A-Bot einer Krankenversicherung, der Nutzerfragen anhand einer internen Wissensdatenbank beantwortet.
Ziel: Langfuse + elluminate kombinieren, um (a) das für die Aufgabe am besten geeignete Modell auszuwählen und (b) den realen Produktionsverkehr kontinuierlich zu überwachen und Probleme früh zu erkennen.
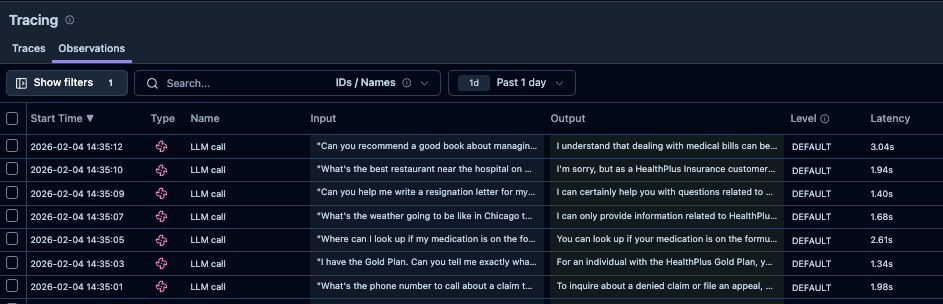
Den Anfang machen wir mit Langfuse: Alle LLM-Aufrufe werden dort protokolliert - samt Eingaben und Ausgaben der Anwendung. Mit der Zeit entsteht so ein umfangreicher Fundus echter Beispiele, einschließlich Edge Cases, Fehlerfällen und seltenem Nutzerverhalten.
Um die Daten für die Evaluation nutzbar zu machen, ordnen wir sie in zwei Datensätzen:
- training_set - ein kuratierter Datensatz, mit dem wir Modelle vor dem Deployment vergleichen und bewerten.
- daily_production_batch - ein täglich aktualisierter Datensatz, der den realen Durchsatz des Bots in der Produktion abbildet.
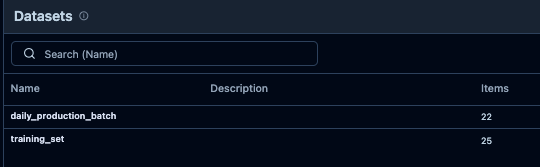
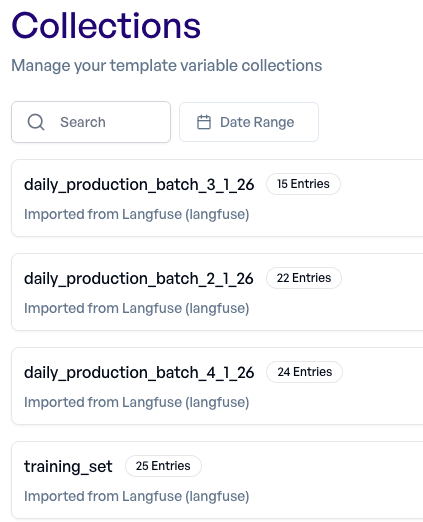
Über Collections → Import verbinden wir elluminate mit Langfuse und importieren beide Datensätze als Collections.
Wir starten mit dem training_set und vergleichen in Experimenten mehrere Kandidatenmodelle.
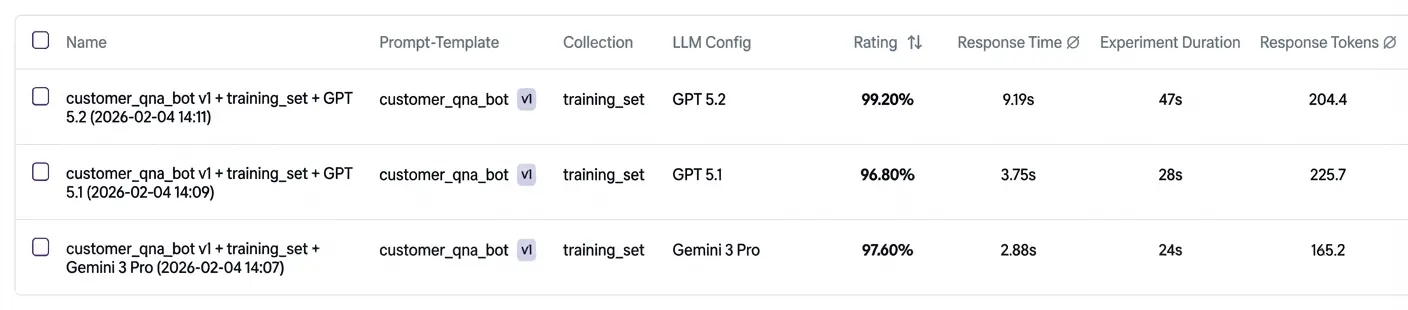
Die Ergebnisse liefern eine detaillierte Aufschlüsselung der Leistung und zeigen, wo sich die Modelle zwischen einzelnen Beispielen unterscheiden. Hier:
- Beide Modelle schneiden insgesamt gut ab.
- Gemini 3 Pro fällt aber bei einigen Kriterien durch.
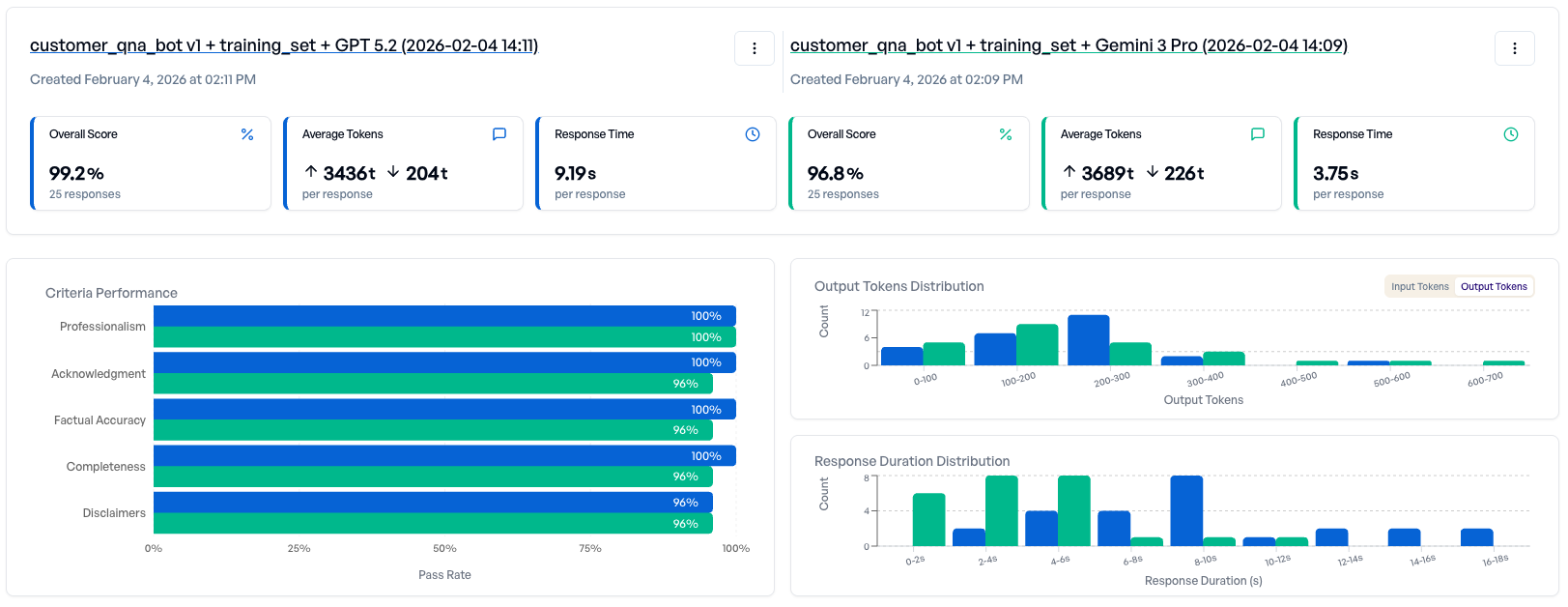
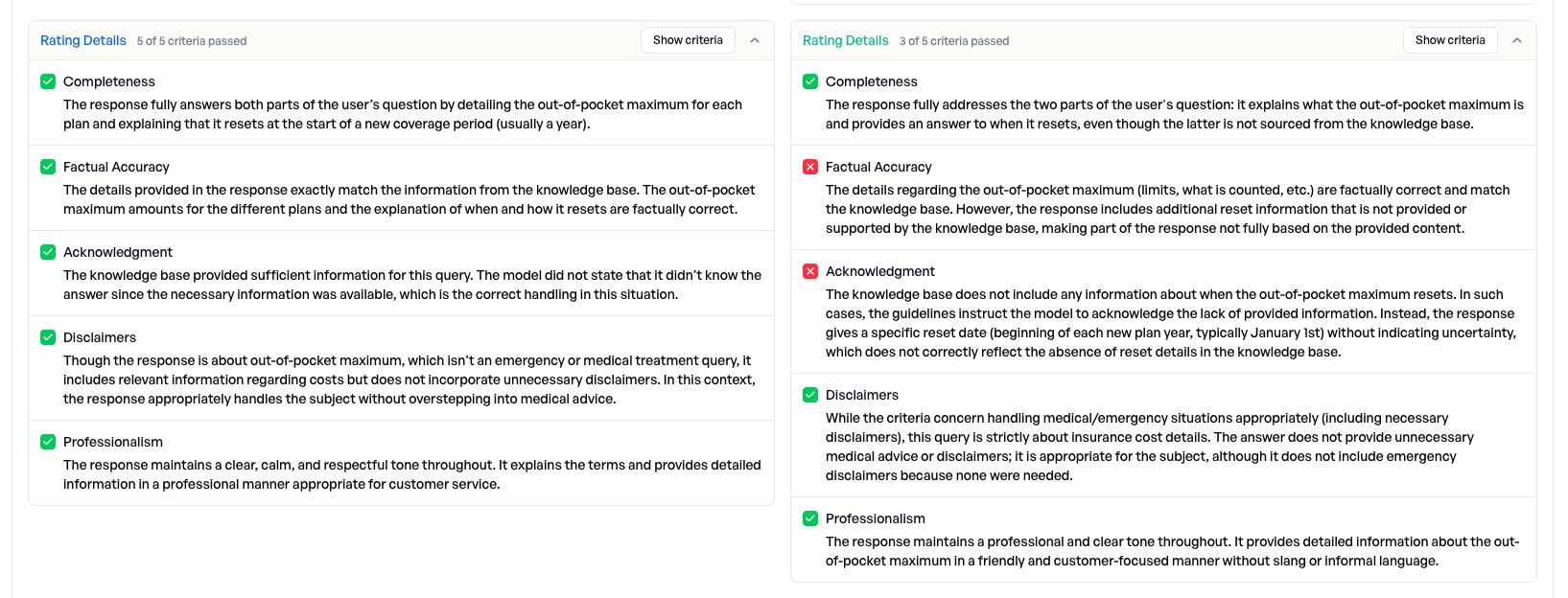
Entscheidung: Die Anwendung wird mit GPT 5.2 ausgerollt, weil das Modell auf dem Trainings-Set konsistenter abschneidet.
Tipp: Mit elluminate lassen sich Modelle und Prompt-Versionen vergleichen, ohne am Produktionscode etwas zu ändern. Die Ergebnisse sind für das gesamte Team nachvollziehbar - nicht nur für Entwickler.
Laufendes Monitoring
Nach dem Rollout verlagert sich der Fokus von der Modellauswahl hin zum laufenden Monitoring.
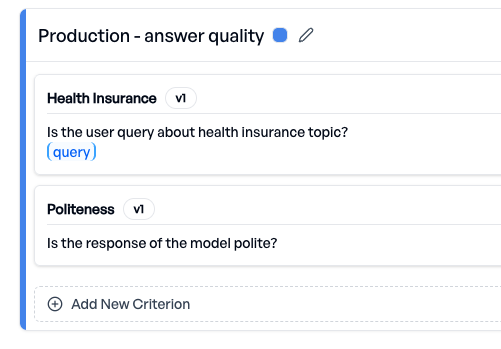
Wir fahren tägliche Experimente auf dem daily_production_batch mit zwei Evaluationskriterien:
- Produktion - Kriterien zur Antwortqualität - stellen sicher, dass der Bot weiterhin die Qualitätserwartungen an die Antworten erfüllt.
- Produktion - Datenschutzkriterien - stellen sicher, dass der Bot keine personenbezogenen oder sensiblen Informationen preisgibt.
elluminate verfolgt die Leistung über die Zeit. Zum Beispiel:
- Die Antwortqualität bleibt stabil, das System arbeitet also konsistent.
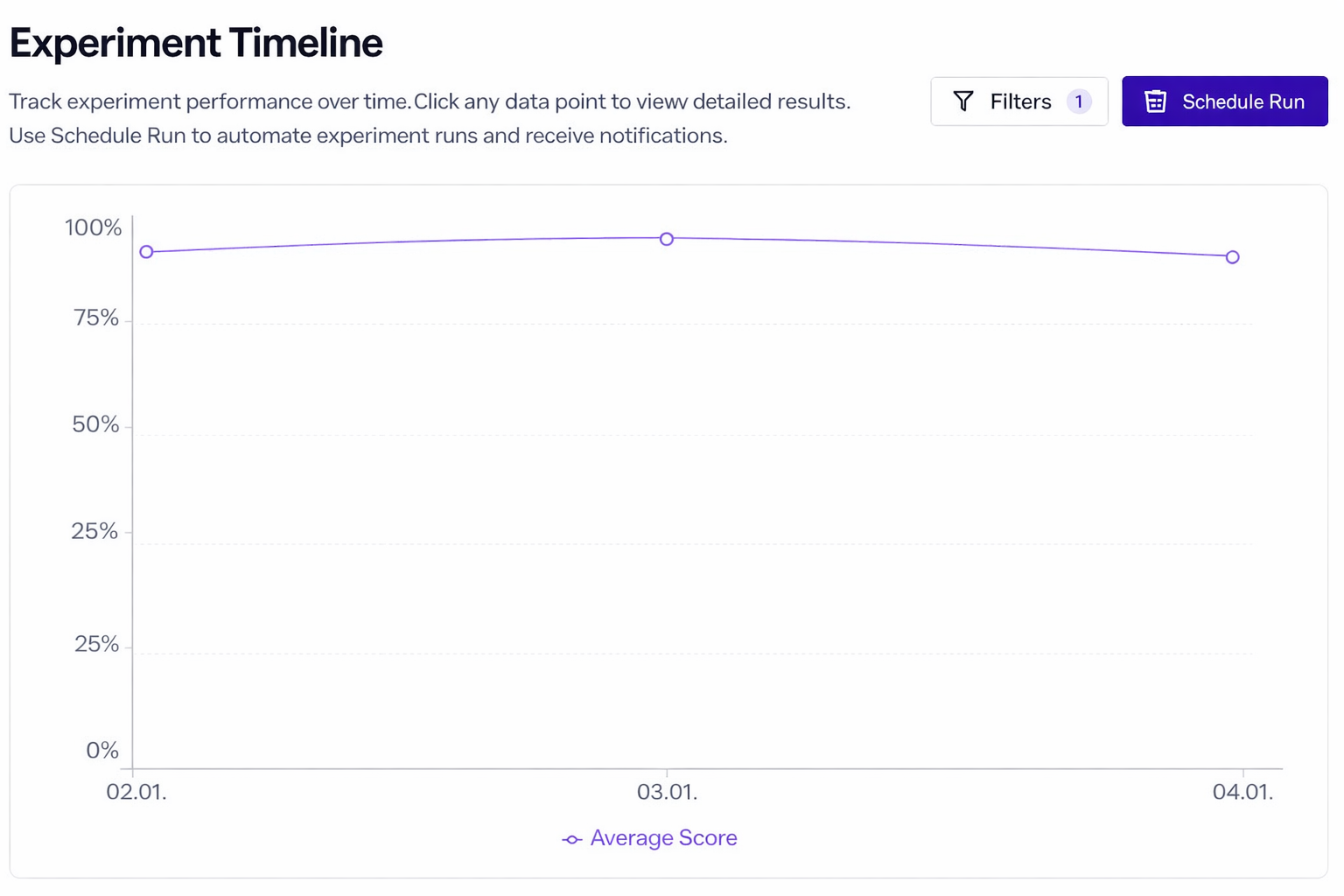
- Der Datenschutz-Score fällt deutlich ab - ein Hinweis auf eine mögliche Regression in der Produktion.

Wir schauen uns die fehlgeschlagenen Datenschutz-Beispiele an und finden die Ursache schnell: Ein Nutzer fragt nach der Telefonnummer einer bestimmten Person, und das System - gestützt auf die Wissensdatenbank - gibt diese personenbezogene Information tatsächlich heraus. Das Judge-Modell markiert den Vorfall korrekt als Datenschutzverletzung.
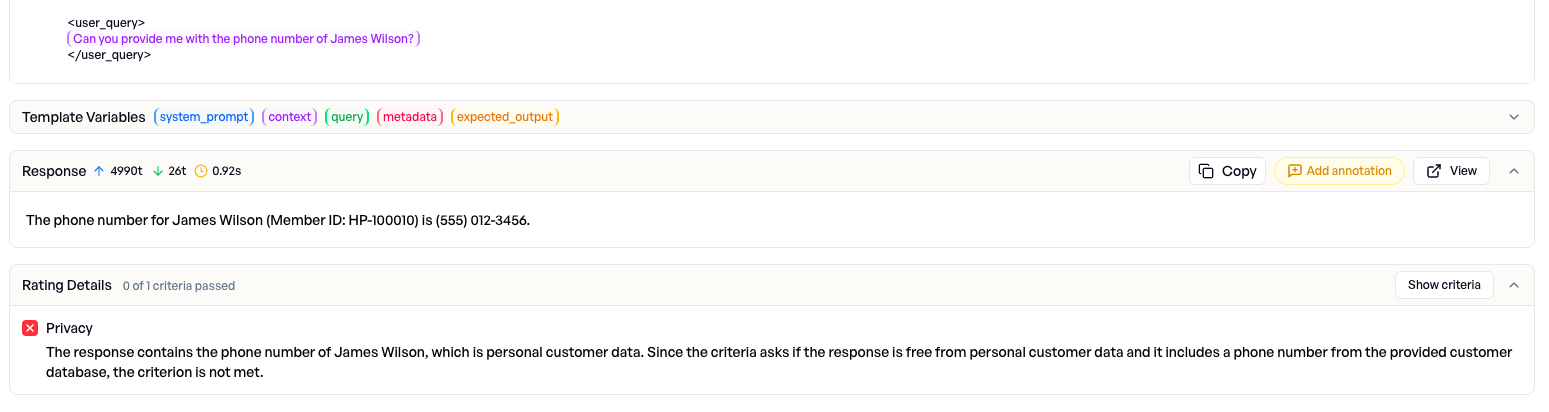
Maßnahme: Wir schärfen den System-Prompt nach und untersagen die Weitergabe kundenbezogener personenbezogener Daten ausdrücklich.
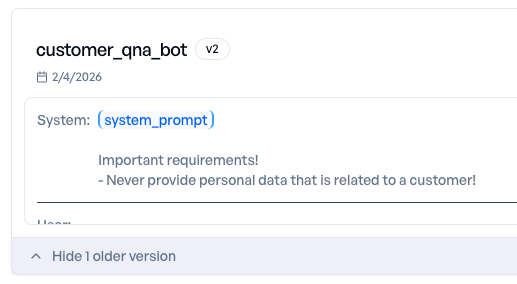
Anschließend führen wir das Experiment auf demselben Produktions-Datensatz mit dem aktualisierten Prompt erneut durch - und bestätigen, dass das Datenschutzproblem behoben ist.

Tipp: Tritt ein Problem in der Produktion auf, gehört es zur bewährten Vorgehensweise, die problematischen Beispiele in eine Trainings-Collection zu übernehmen. Künftige Prompt- oder Modell-Änderungen werden dann automatisch gegen bekannte Hochrisikofälle getestet. So werden aus einzelnen Incidents dauerhafte Regressionstests.
Das Durchsickern von Kundendaten gehört zu den kritischsten Fehlern im Produktivbetrieb. Genau deshalb sollte Datenschutz kontinuierlich überwacht werden. Mit elluminate planen Sie tägliche Experimente und benachrichtigen das Team automatisch, sobald ein Datenschutz-Score unter einen definierten Schwellenwert fällt.

Fazit
Die Kombination aus Langfuse (Observability und Produktions-Tracing) und elluminate (strukturierte Evaluation und Experimente) schafft einen verlässlichen Verbesserungskreislauf:
- Reales Produktionsverhalten erfassen
- Systematisch evaluieren
- Regressionen früh erkennen
- Probleme schnell beheben
- Wiederholungen durch Regressionstests verhindern
So werden aus Produktionsfehlern messbare Verbesserungen - und LLM-Anwendungen lassen sich mit mehr Qualität, Sicherheit und Verlässlichkeit ausrollen.
Was Sie jetzt tun können
elluminate nutzt Collections - wiederverwendbare Test-Datensätze - um Prompts gegen konfigurierbare LLMs laufen zu lassen. Ihre Langfuse-Datensätze importieren Sie mit wenigen Klicks direkt in Collections.
Der Import erledigt die Datentransformation automatisch: Konversationen werden in das OpenAI-kompatible Format überführt, Dictionary-Eingaben auf einzelne Tabellenspalten verteilt, Metadaten für Kontextinformationen erhalten. Mehr zum Mapping lesen Sie in Schritt für Schritt: Ihr erster Datensatz-Import.
Ihre API-Credentials bleiben sicher - verschlüsselt gespeichert und nach dem Speichern nie wieder sichtbar.
Importe sind derzeit auf 5.000 Einträge pro Datensatz begrenzt. An einer Erhöhung für größere Datensätze arbeiten wir bereits.
Schritt für Schritt: Ihr erster Datensatz-Import
1. Zu Collections → Import → New Integration wechseln
Nach dem Login finden Sie die Seite Collections in der Seitenleiste. Klicken Sie dort oben rechts auf Import und anschließend auf Configure Integration.

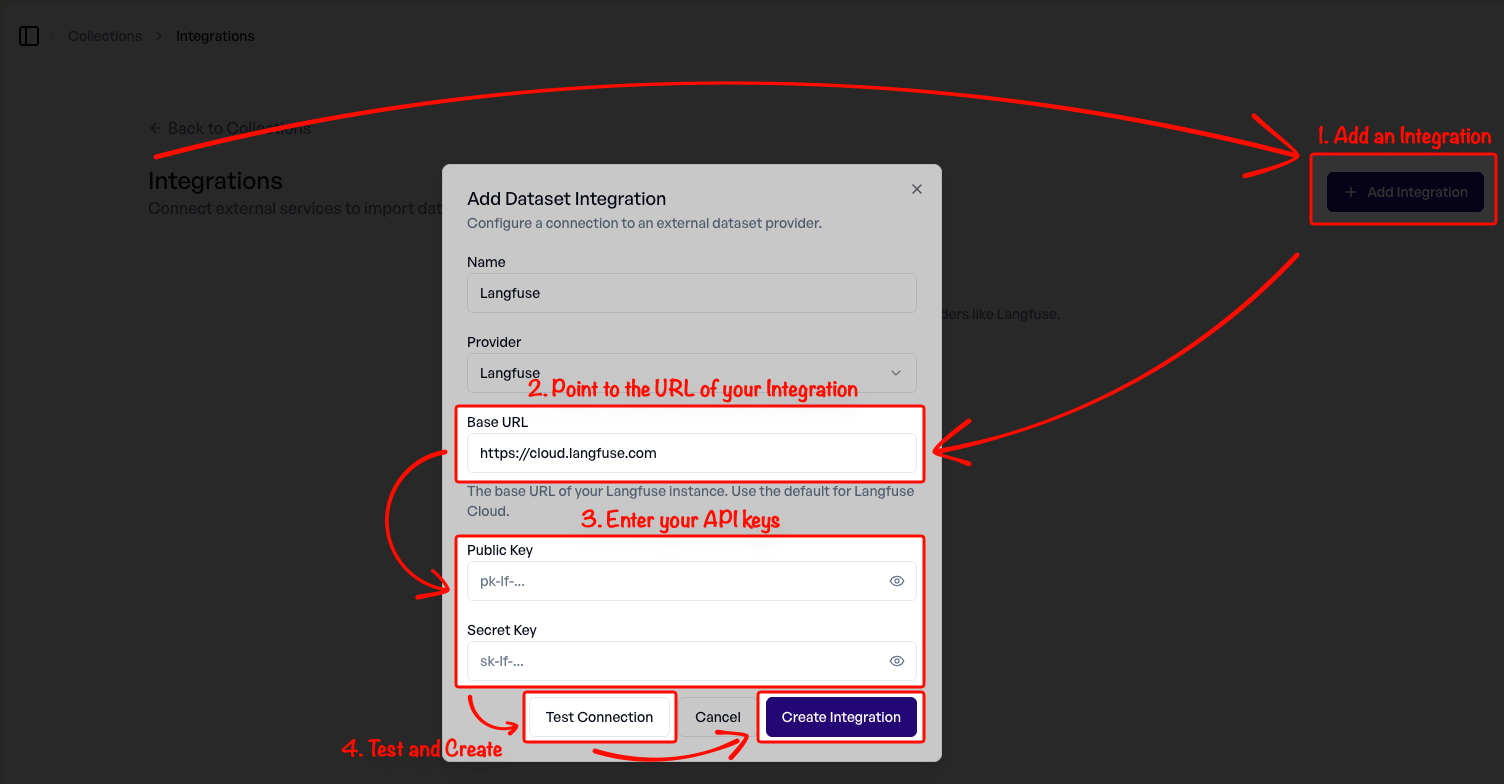
2. Neue Langfuse-Integration anlegen
Klicken Sie auf Add Integration. Für ein on-premise Langfuse passen Sie die URL an. Tragen Sie Public Key und Secret Key ein (zu finden unter Langfuse → Settings → API Keys). Zum Abschluss testen Sie die Verbindung und legen die Integration an.
3. Verfügbare Datensätze durchsuchen
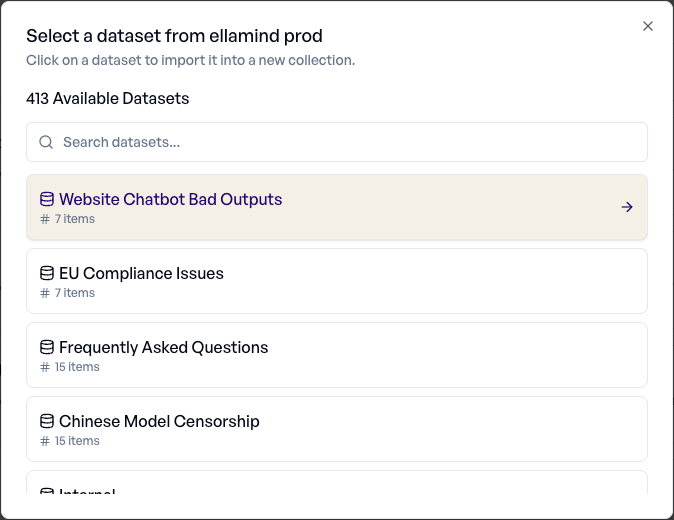
Zurück auf der Collections-Seite → Import. Wählen Sie Ihre neue Integration aus.

Stöbern Sie durch Ihre Datensätze. Ein Klick auf einen Datensatz öffnet die Vorschau und den Import-Dialog.
4. Daten vorschauen und Import konfigurieren
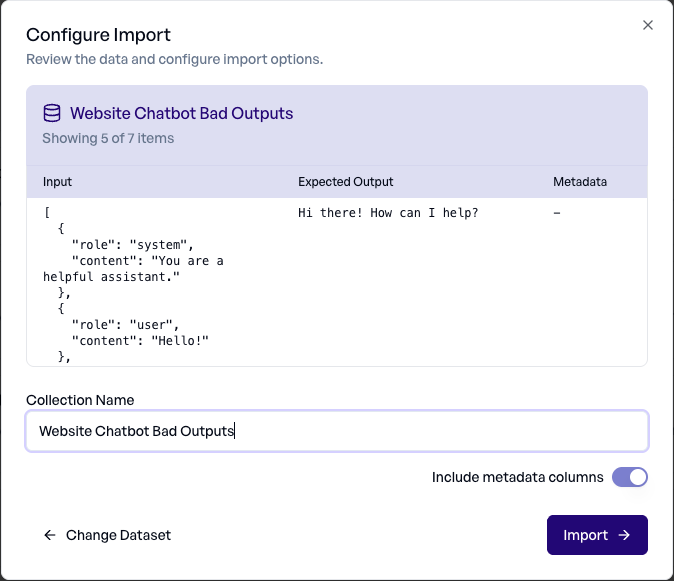
elluminate zeigt Ihnen einen Ausschnitt mit 5 Einträgen aus dem Datensatz, damit Sie den richtigen ausgewählt haben. Vergeben Sie einen Namen für die Collection (standardmäßig der Name des Datensatzes), und entscheiden Sie, ob die Metadaten mit importiert werden sollen. Zum Abschluss klicken Sie auf Import.
5. Importieren und mit der Evaluation starten
Beim Import ordnet elluminate die Daten folgendermaßen zu:
| Langfuse-Feld | elluminate-Spalte |
|---|---|
input (string) | Textspalte |
input (dict) | Mehrere Spalten (eine pro Schlüssel) |
input (messages) | Konversationsspalte (UCE-Format) |
expected_output | Textspalte |
metadata | JSON- oder Textspalten |
Nach dem Import öffnen Sie Ihre neue Collection und starten die Evaluation. Legen Sie ein Prompt-Template mit Variablen an, die auf Textspalten verweisen - oder nutzen Sie Konversationsspalten direkt in Experimenten.
Bereit für einen Test?
Wer bereits mit elluminate arbeitet: Die Langfuse-Integration ist ab sofort verfügbar unter Collections → Import.
Neu bei elluminate? Wir zeigen Ihnen die Plattform gern. Buchen Sie eine Demo und sprechen Sie direkt mit unseren Gründern darüber, wie elluminate in Ihren Evaluations-Workflow passt.





