Ein Framework für systematische RAG-Evaluation – vom Testdesign bis zum Monitoring im Produktivbetrieb.
Ein Chatbot einer Krankenversicherung teilt einem Kunden mit, kosmetische Eingriffe seien nicht abgedeckt. Der Kunde akzeptiert die Antwort und hakt das Thema ab. Dabei übernimmt die Versicherung bestimmte kosmetische Eingriffe sehr wohl – das entsprechende Leistungsdokument war nur nicht im Retrieval-Index des Chatbots hinterlegt. Keine Halluzination. Kein offensichtlicher Fehler. Nur eine leise, selbstsicher formulierte Falschauskunft, die aussieht wie eine korrekte Antwort.
Genau das ist die Kernherausforderung bei der RAG-Evaluation: Die Fehler, die am stärksten ins Gewicht fallen, sind in der Antwort selbst meist unsichtbar. Das System hat Dokumente gefunden, das LLM hat eine plausibel klingende Antwort erzeugt, und niemand schaut genauer hin – nur war die Antwort eben falsch. Wie fangen Sie solche Fälle ab, bevor es Ihre Nutzer tun? Darum geht es in diesem Beitrag.
Wir gehen einen vollständigen Evaluations-Workflow anhand einer Fallstudie durch: einen RAG-gestützten Chatbot für die fiktive deutsche Krankenversicherung Sehr Gute Krankenkasse (SGKK), der Mitgliederfragen zu Leistungen, Zuzahlungen und Ansprüchen beantwortet. Der Ansatz deckt Testdaten-Design, gezielte Evaluationskriterien, Experimentauswertung und kontinuierliches Monitoring im Produktivbetrieb ab.
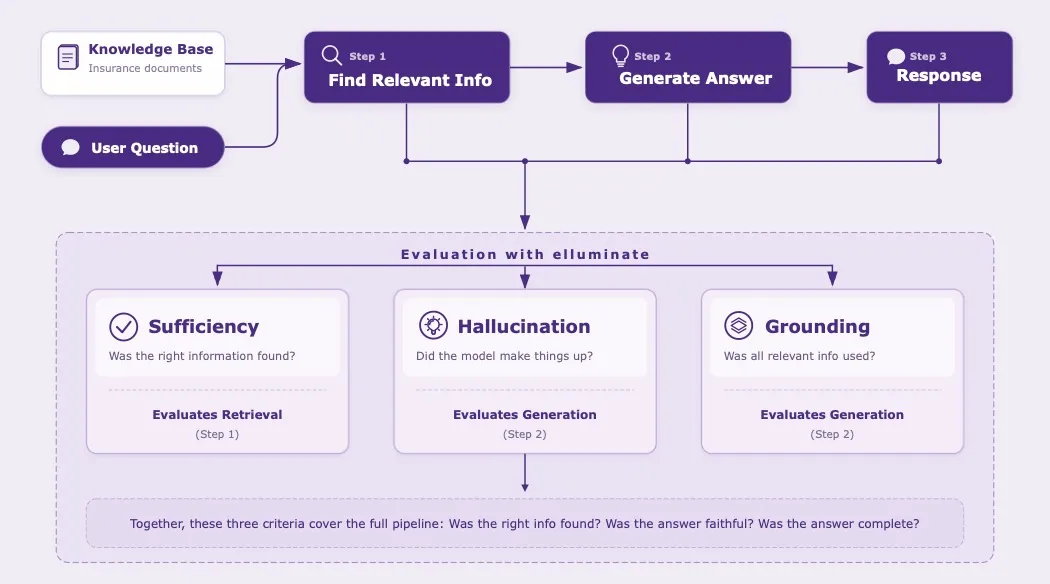
Das Evaluations-Framework
Aufbau des Testdatensatzes
Ein gut strukturierter Testdatensatz ist das Fundament jeder RAG-Evaluation. Statt das System mit zufälligen Fragen zu bombardieren, haben wir einen Testdatensatz entworfen, der zwei Klassifikationsachsen kombiniert – das ermöglicht später eine gezielte Auswertung:
Achse 1: Schwierigkeit
- Einfach – Direkte Antworten aus einem einzelnen Dokument. „Was übernimmt die SGKK bei Zahnersatz?”
- Mittel – Erfordert Kontextverständnis und das Kombinieren von Informationen. „Wie hoch ist das Krankengeld für Angestellte?”
- Schwer – Erfordert die Synthese mehrerer Dokumente oder deckt komplexe Themen ab. „Welche Vorteile bietet die SGKK gegenüber anderen Versicherern?”
- Nicht beantwortbar – Fragen, die das System nicht beantworten soll, weil sie entweder außerhalb der Wissensdatenbank oder komplett außerhalb der Domäne liegen.
Achse 2: Thema
- Versicherungsbezogen – Legitime Fragen rund um die Krankenversicherung, inklusive einiger Themen, die nicht in der Wissensdatenbank stehen („Übernimmt die SGKK eine LASIK-Operation?”).
- Nicht versicherungsbezogen – Fragen komplett außerhalb der Domäne („Wie wird das Wetter morgen?”, „Gibst du mir ein Lasagne-Rezept?”).
Diese zweiachsige Kategorisierung zahlt sich bei der Auswertung aus. Statt auf einen einzigen aggregierten Score zu starren, können Sie die Daten filtern und verstehen, wo und warum Ihr System versagt – und ob diese Fehler überhaupt relevant sind.
Zusätzlich zum statischen Testdatensatz haben wir ein tägliches Monitoring im Produktivbetrieb aufgesetzt: Jeden Tag wird ein Batch echter Nutzerfragen mit denselben Kriterien evaluiert. So lassen sich Regressionen abfangen, bevor sie eine nennenswerte Zahl von Nutzern treffen.
Evaluationskriterien
Nicht jeder RAG-Fehler ist gleich. Ein System, das Informationen erfindet, ist schlimmer als eines, das schlicht das richtige Dokument nicht findet. Um diese Unterschiede abzubilden, haben wir drei gezielte Evaluationskriterien definiert:
Sufficiency – Reichen die Informationen in den abgerufenen Chunks aus, um die Anfrage zu beantworten?

Dieses Kriterium bewertet ausschließlich die Retrieval-Komponente. Die LLM-Antwort bleibt außen vor; es zählt nur, ob die abgerufenen Chunks die zur Beantwortung nötigen Informationen enthalten. Scheitert Sufficiency, hat die Retrieval-Pipeline die richtigen Dokumente nicht gefunden – unabhängig davon, was das LLM aus dem Kontext gemacht hat.
Hallucination – Ist die Antwort frei von Halluzinationen? Vergleichen Sie sie mit den Informationen aus dem gegebenen Kontext.

Dieses Kriterium prüft, ob das LLM dem bereitgestellten Kontext treu geblieben ist. Hat es Fakten erfunden? Hat es Leistungen bestätigt, die in den abgerufenen Dokumenten gar nicht stehen? Im Kontext einer Krankenversicherung können halluzinierte Informationen Mitglieder direkt über ihre Ansprüche in die Irre führen.
Grounding – Bezieht die Antwort alle relevanten Informationen aus dem Kontext ein, um die Nutzerfrage zu beantworten?

Dieses Kriterium prüft, ob das LLM die abgerufenen Informationen tatsächlich verwendet hat. Wenn die Chunks relevante Details enthalten, die das Modell ignoriert, ist die Antwort unvollständig – auch wenn nichts halluziniert wurde.
Zusammen decken diese drei Kriterien die gesamte RAG-Pipeline ab: Wurden die richtigen Informationen gefunden? (Sufficiency) Ist das Modell ihnen treu geblieben? (Hallucination) Hat das Modell sie auch tatsächlich genutzt? (Grounding)
Experimente und Ergebnisse
Gesamtergebnisse
Der vollständige Testdatensatz mit 47 Anfragen liefert für unser RAG-System einen Gesamtscore von 90,1 %.
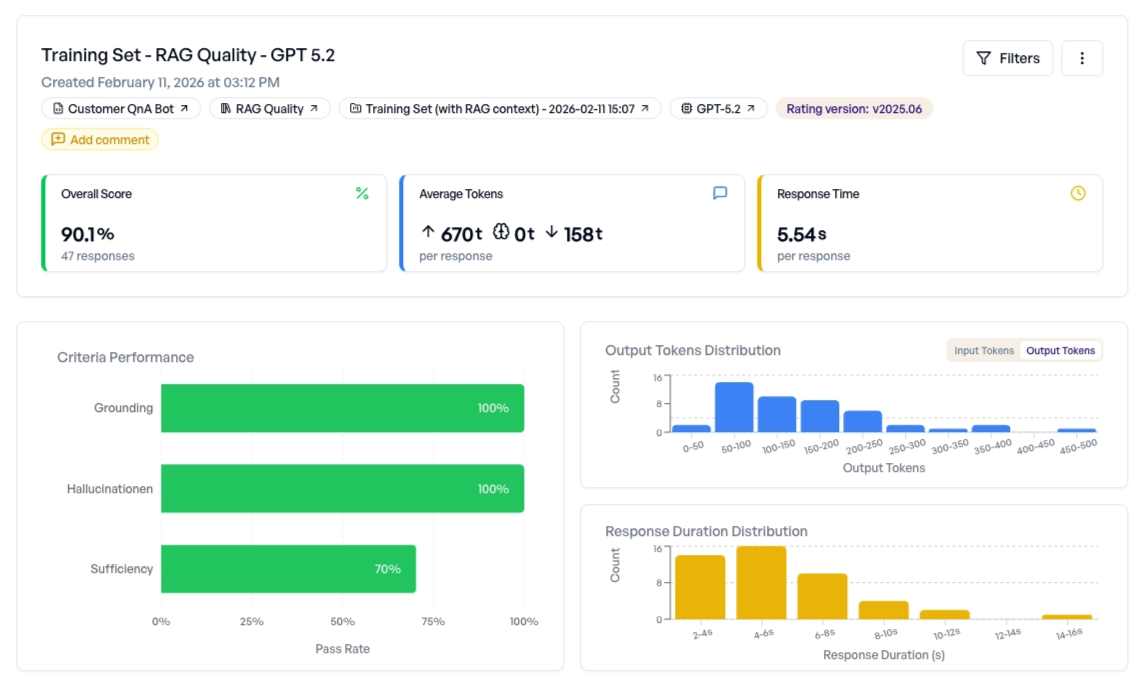
Nach Kriterium aufgeschlüsselt:
- Grounding: 100 % – Das Modell bezieht den abgerufenen Kontext konsequent in seine Antworten ein.
- Hallucination: 100 % – Das Modell erfindet nie Informationen, die über den Kontext hinausgehen.
- Sufficiency: 70 % – Die Retrieval-Pipeline findet nicht immer die richtigen Informationen.
Das Muster ist eindeutig: Das LLM selbst arbeitet perfekt, die Retrieval-Komponente ist das schwache Glied. Eine Sufficiency von 70 % bedeutet, dass bei etwa jeder dritten Anfrage die abgerufenen Dokumente nicht enthalten, was zur Beantwortung nötig wäre.
Aber ist das tatsächlich ein Problem? Genau hier werden die Kategorienfilter unbezahlbar.
Wo Fehler tatsächlich ins Gewicht fallen
Filtert man auf ausschließlich versicherungsbezogene Anfragen – also die Fragen, die das System überhaupt beantworten soll –, springt der Gesamtscore auf 92,1 % und Sufficiency steigt von 70 % auf 76 %. Einige Retrieval-Fehler ballen sich in Anfragen, die thematisch am Einsatzgebiet vorbeigehen. Bei den Fragen, für die das System gebaut wurde, funktioniert das Retrieval deutlich besser.
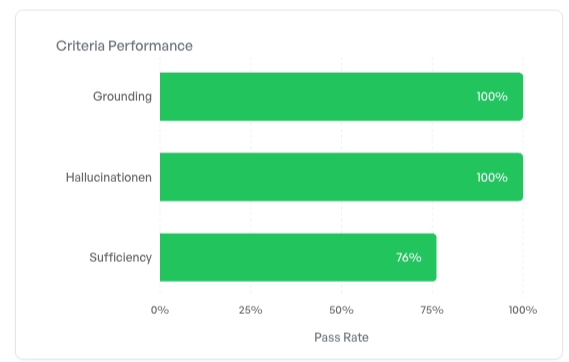

Am anderen Ende des Spektrums stehen themenfremde Anfragen wie „Wie wird das Wetter morgen?”: Hier liegt Sufficiency bei gerade einmal 20 % – nahezu alle Retrieval-Versuche finden keinen relevanten Kontext. Und das ist genau das richtige Verhalten. Die Retrieval-Pipeline soll in einer Wissensdatenbank zur Krankenversicherung keine relevanten Chunks zum Wetter finden. Da Grounding und Hallucination weiterhin bei 100 % liegen, geht das Modell souverän mit fehlendem Kontext um: Es erfindet keine Antworten.
Ohne die zweiachsige Kategorisierung bliebe diese Differenzierung unsichtbar. Wir würden nur einen Sufficiency-Score von 70 % sehen und uns fragen, was da schiefläuft. Mit sauberer Kategorisierung erkennen wir sofort, dass die „Fehler” sich genau dort häufen, wo sie sich häufen sollen – und können unsere Aufmerksamkeit auf die Fälle lenken, die wirklich zählen.
Den Kreis mit Fachexperten schließen
Doch 76 % Sufficiency bei Versicherungsfragen bedeutet eben auch: Einige legitime Fragen fallen durch. An dieser Stelle wird der Human-in-the-Loop unverzichtbar.
Nehmen wir das Beispiel der kosmetischen Eingriffe aus der Einleitung. Die automatisierte Evaluation hat den Sufficiency-Fehler korrekt identifiziert – die abgerufenen Chunks behandelten zahnärztliche Leistungen, Krebsvorsorge und Auslandsversicherung, aber nichts zu kosmetischen Eingriffen. Das System hat die Antwort korrekt verweigert.
Aber ist das ein Problem, das behoben werden muss? Diese Einschätzung kann nur jemand mit Fachwissen treffen:
- Falls die SGKK kosmetische Eingriffe tatsächlich abdeckt und die Information in der Wissensdatenbank stehen sollte, liegt ein echter Retrieval-Fehler vor, der Aufmerksamkeit braucht.
- Falls die SGKK diese Leistung nicht übernimmt, ist das erwartetes Verhalten.
In diesem Fall hat ein Fachexperte den Fehler geprüft und ein reales Problem erkannt: Die SGKK übernimmt bestimmte kosmetische Eingriffe sehr wohl, das entsprechende Leistungsdokument wurde jedoch nie in die Wissensdatenbank aufgenommen. Er hat den Befund dokumentiert und damit einen vagen „Sufficiency-Fehler” in eine konkrete, umsetzbare Aufgabe überführt: das Leistungsdokument zu kosmetischen Eingriffen einpflegen. Wenn das Retrieval-Team das fehlende Dokument ergänzt und das Experiment erneut laufen lässt, sieht es sofort, ob dieser konkrete Fehler behoben ist – der Kreis von Entdeckung bis Fix schließt sich.
Dieser Feedback-Loop zwischen Fachexperten und Entwicklerteams macht RAG-Evaluation praxistauglich. Die automatisierten Kriterien bringen die relevanten Fälle an die Oberfläche; die Fachexperten liefern die Einschätzungen, die automatisierte Systeme aus sich heraus nicht treffen können.
Vom Testen zum Monitoring im Produktivbetrieb
Dieselben Kriterien, die den Testdatensatz validiert haben, können auch den Produktivbetrieb kontinuierlich überwachen. Jeden Tag wird ein Batch echter Nutzerfragen – jeweils mit dem zugehörigen abgerufenen Kontext – automatisch evaluiert.
Über fünf Tage hinweg zeichnen die täglichen Scores ein klares Bild:
| Tag | Gesamt | Grounding | Hallucination | Sufficiency |
|---|---|---|---|---|
| Tag 1 | 86,7 % | 100 % | 100 % | 60 % |
| Tag 2 | 96,7 % | 100 % | 100 % | 90 % |
| Tag 3 | 90,0 % | 100 % | 100 % | 70 % |
| Tag 4 | 90,0 % | 100 % | 90 % | 80 % |
| Tag 5 | 93,3 % | 100 % | 100 % | 80 % |
Grounding und Hallucination sind nahezu perfekt, während Sufficiency je nach Themenmix der Anfragen schwankt. Tag 4 bringt allerdings etwas Neues zum Vorschein: einen Hallucination-Fehler. Ein Nutzer fragte „Wo finde ich meine Versichertennummer?”, und das Modell antwortete selbstsicher, die Nummer stehe auf der Versichertenkarte und sei über die Service-App einsehbar. Der abgerufene Kontext erwähnte Versichertennummer und App, bestätigte aber nie explizit, dass die Nummer auf der Karte aufgedruckt ist. Das Modell hat das geschlussfolgert – eine plausible Annahme, die so aber nicht durch die Quellen gedeckt ist.
Genau solche feinen Fehler zählen im Produktivbetrieb. Die Antwort ist plausibel, aber in einer regulierten Domäne ist der Unterschied zwischen „wahrscheinlich korrekt” und „durch Quellen belegt” entscheidend.
Tägliches Monitoring im Produktivbetrieb bringt drei zentrale Vorteile:
- Frühwarnung. Wenn der Retrieval-Index beschädigt wird, ein Modell-Update Regressionen einführt oder die Wissensdatenbank veraltet, fängt die tägliche Evaluation das ab, bevor Nutzer es bemerken.
- Trend-Sichtbarkeit. Statt anekdotischer Rückmeldungen haben Sie objektive Kennzahlen über die Zeit – aufgeschlüsselt nach Kriterium, sodass Sie wissen, was sich verändert hat, nicht nur dass sich etwas verändert hat.
- Umsetzbare Diagnostik. Wenn ein Score sinkt, zeigt die Aufschlüsselung nach Kriterium, ob es ein Retrieval-Problem (Sufficiency), ein Generierungs-Problem (Hallucination) oder ein Vollständigkeitsproblem (Grounding) ist – und verweist direkt auf die Komponente, die zu prüfen ist.
Was RAG-Evaluation wirklich funktionieren lässt
- Strukturieren Sie Ihren Testdatensatz bewusst. Eine zweiachsige Kategorisierung verwandelt eine flache Liste von Testfragen in ein Diagnosewerkzeug. Wenn etwas schiefgeht, lässt sich sofort eingrenzen, ob es ein Retrieval-Problem, ein Generierungs-Problem oder schlicht erwartetes Verhalten ist.
- Entwerfen Sie Kriterien, die Fehlermodi isolieren. Sufficiency, Hallucination und Grounding zielen jeweils auf eine andere Komponente der RAG-Pipeline. Wenn ein Score fällt, wissen Sie genau, wo Sie suchen müssen.
- Akzeptieren Sie, dass nicht alle Fehler gleich zählen. Eine Sufficiency von 0 % bei themenfremden Anfragen ist ein Feature, kein Bug. Die automatisierte Evaluation bringt die Fälle an die Oberfläche; Fachexperten liefern die Einschätzung. Diesen Human-in-the-Loop in den Evaluations-Workflow einzubauen, ist entscheidend.
- Überwachen Sie den Produktivbetrieb kontinuierlich. Ein Testdatensatz validiert Ihr System unter kontrollierten Bedingungen. Das Monitoring im Produktivbetrieb validiert es unter realen Bedingungen, jeden Tag, mit der chaotischen Vielfalt echter Nutzerfragen.
Ein RAG-System zu bauen, ist der erste Schritt. Zu wissen, dass es funktioniert – und das fortlaufend zu belegen –, bringt es in den Produktivbetrieb und hält es dort.
Sie suchen technische Umsetzungsdetails? Einen hands-on Leitfaden mit dem elluminate SDK – inklusive Codebeispielen für den programmatischen Aufbau von Evaluations-Pipelines – finden Sie in unserer RAG-Evaluations-Dokumentation.
Möchten Sie Ihre RAG-Anwendung evaluieren?
Ob kundenseitiger Chatbot oder interner Wissensassistent – elluminate gibt Ihnen die Werkzeuge, systematisch zu evaluieren: vom Testdesign bis zum Monitoring im Produktivbetrieb. Wir unterstützen Sie gern beim Einstieg.





