Im Dezember 2025 hat OpenAI FrontierScience veröffentlicht, den bis dahin härtesten öffentlichen Science-Benchmark. Seitdem ist eine neue Generation von Frontier-Modellen erschienen: GPT-5.4, Claude Opus 4.6 und Gemini 3.1 Pro. Jedes davon verspricht einen deutlichen Leistungssprung. Zeit, den Stand der Dinge zu prüfen. In diesem Beitrag lassen wir den Benchmark mit elluminate auf den aktuellen Modellen erneut laufen und analysieren die Ergebnisse.
Der FrontierScience-Benchmark von OpenAI
Mit den wachsenden Reasoning-Fähigkeiten aktueller KI-Modelle kommen bestehende Science-Benchmarks kaum noch hinterher. GPQA[2] galt einmal als extrem schwierig, doch in den letzten zwei Jahren sind die Modell-Scores von 39 % auf 92 % gestiegen. FrontierScience ist bewusst härter, origineller und aussagekräftiger angelegt. Der Benchmark umfasst 160 Aufgaben aus Physik, Chemie und Biologie, erstellt von 42 internationalen Olympia-Medaillengewinnern und 45 promovierten Forschern. Jede Aufgabe wurde unabhängig fachlich begutachtet, und alle Aufgaben, die OpenAIs interne Modelle bereits lösen konnten, wurden während der Erstellung aussortiert. Das macht das spätere starke Abschneiden von GPT-5.4 besonders interessant. Hier eine der einfacheren Aufgaben aus dem Olympiade-Set Chemie:
Aufgabe: Chlorperchlorat (Cl₂O₄) ist ein interessantes Chloroxid. Die Chloratome haben unterschiedliche Oxidationsstufen. Was ist das Produkt ihrer Oxidationsstufen?
Antwort: 7
Das ist noch am leichteren Ende. Die meisten Aufgaben sind deutlich anspruchsvoller. Sie verlangen mehrstufige Syntheseketten, umfangreiche Herleitungen oder experimentelle Versuchsplanungen, die Wissen aus mehreren Teilgebieten verknüpfen.
Der Benchmark besteht aus zwei Teilsätzen. Olympiad enthält 100 Aufgaben mit genau einer korrekten Antwort: eine Zahl, Gleichung, Formel oder kurze Wortangabe. Research enthält 60 offene Teilaufgaben, die repräsentativ für den Arbeitsalltag eines promovierten Forschers sind. Jede davon ist auf drei bis fünf Stunden Bearbeitungszeit ausgelegt und wird nach einer 10-Punkte-Skala bewertet.
Für diese Evaluation konzentrieren wir uns auf den Olympiad-Teil: 100 schwere Aufgaben mit verifizierbaren Antworten. So haben wir das Ganze in elluminate aufgesetzt.
Datensatz importieren
OpenAI hat den FrontierScience-Datensatz frei zugänglich auf HuggingFace veröffentlicht. Den Olympiad-Teil in elluminate zu importieren ist mit dem Python-SDK schnell erledigt: Wir filtern den Research-Track heraus (seine Antworten beginnen mit “Points:”), entfernen die im Datensatz eingebetteten Instruktionen und legen eine Collection an:
import datasets as hfds
from elluminate import Client
COLUMNS = ["problem", "reference_answer", "subject"]
# Full instruction text truncated for readability
INSTRUCTION_OLYMPIAD = 'Think step by step and solve the problem below. At the end of ...'
client = Client()
ds_en = hfds.load_dataset("openai/frontierscience") ["test"]
ds_en = ds_en.filter(lambda x: "Points:" not in x["answer"])
ds_en = ds_en.map(lambda x: {"problem": x["problem"].replace(INSTRUCTION_OLYMPIAD, "").strip()})
ds_en = ds_en.rename_column("answer", "reference_answer")
client.create_collection(
name="FrontierScience Olympiad",
variables=ds_en.select_columns(COLUMNS).to_list(),
)So sieht das Ergebnis in der Web-UI aus:
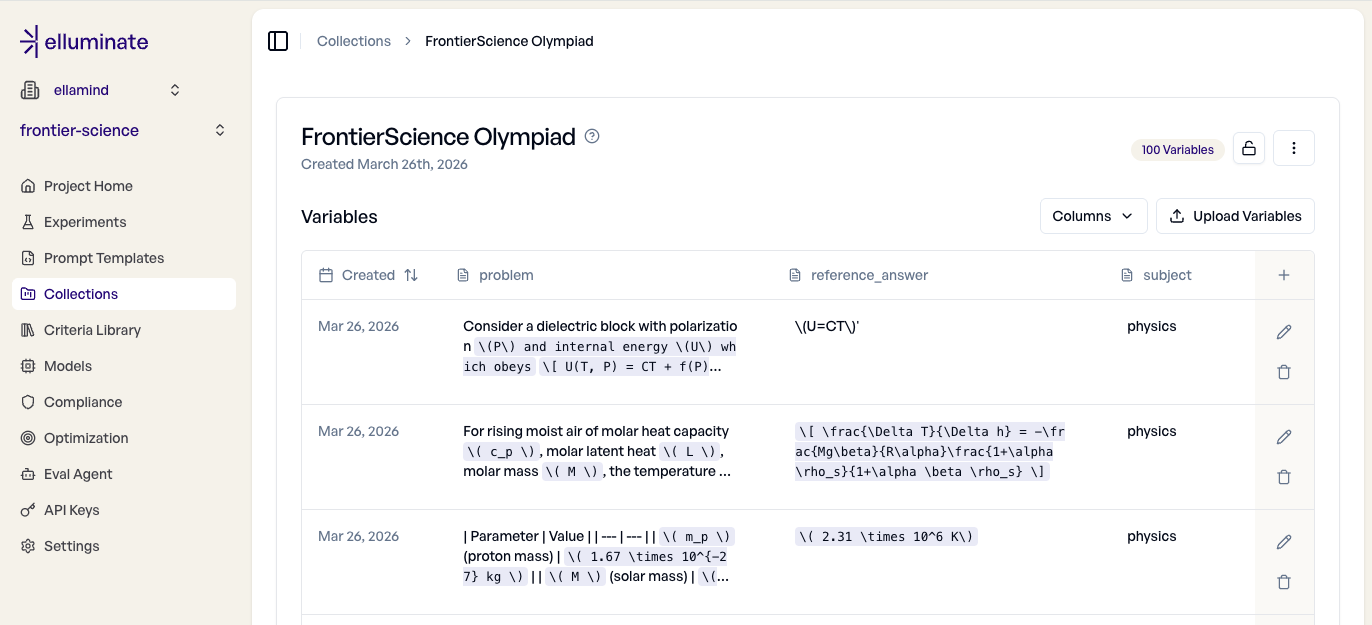
Die Spalte subject ermöglicht uns später das Filtern nach Fachgebiet, sodass wir die Modell-Leistung zwischen Biologie, Chemie und Physik vergleichen können.
Prompt-Template und Kriterien einrichten
Neben der Collection brauchen wir noch zwei Dinge: ein Prompt-Template, das dem Modell sagt, was zu tun ist, und eine Reihe von Kriterien, nach denen das Rating-Modell die Antworten bewertet.
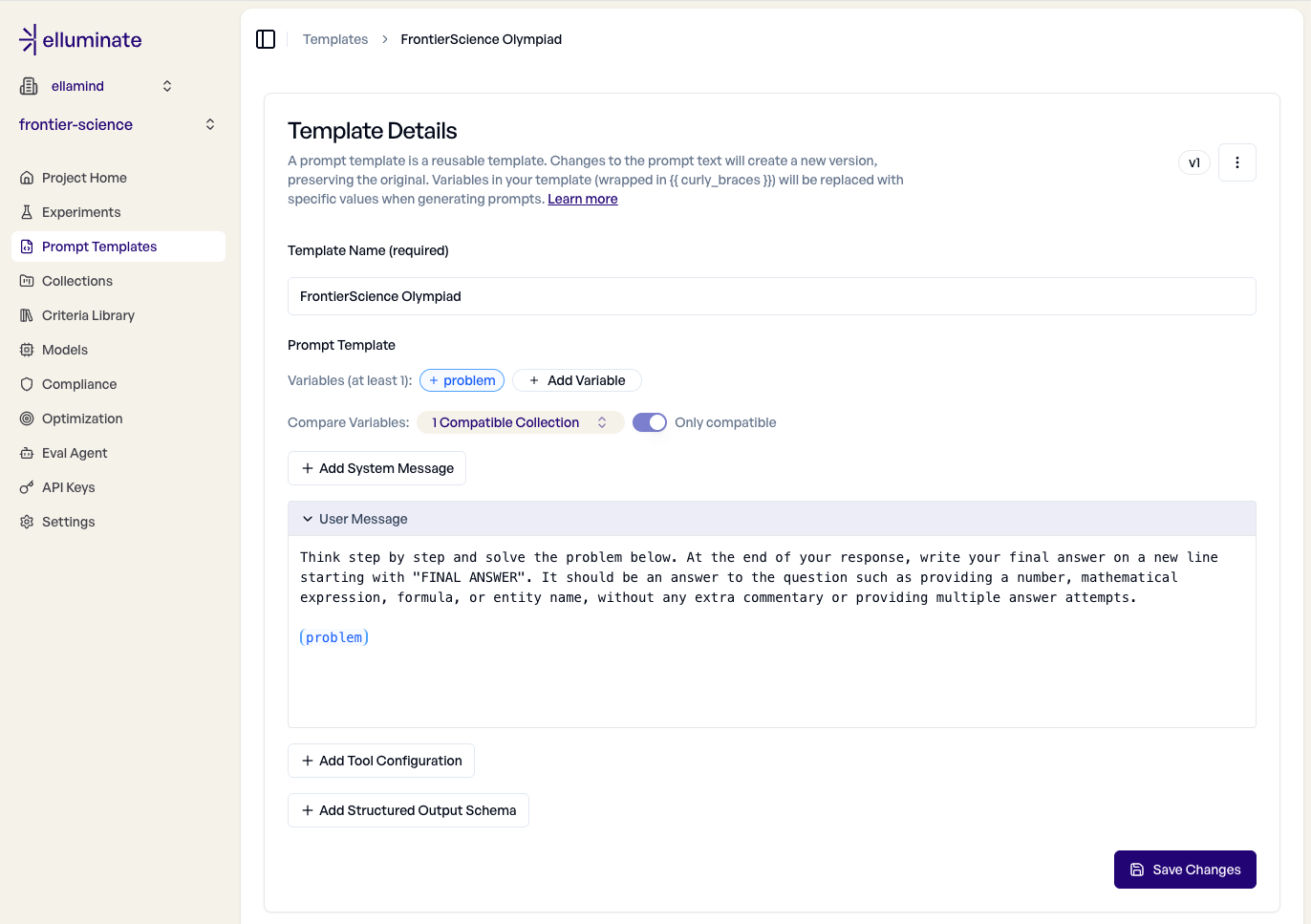
In Anlehnung an OpenAIs FrontierScience-Implementierung umrahmt unser Prompt-Template jede Aufgabe mit der Anweisung, schrittweise zu lösen und eine finale Antwort zu formulieren. Jeder (problem)-Platzhalter wird zur Evaluation durch eine Aufgabe aus der Collection ersetzt.
Für die Evaluation des Olympiad-Teils von FrontierScience reicht ein einziges Kriterium: Stimmt die finale Antwort des Modells mit der Referenz überein? Dabei wollen wir auch äquivalente Formen akzeptieren: übereinstimmende algebraische Ausdrücke, Zahlen im Rahmen einer Rundung auf eine Nachkommastelle, äquivalente Verbindungsnamen und Einheitenumrechnungen.
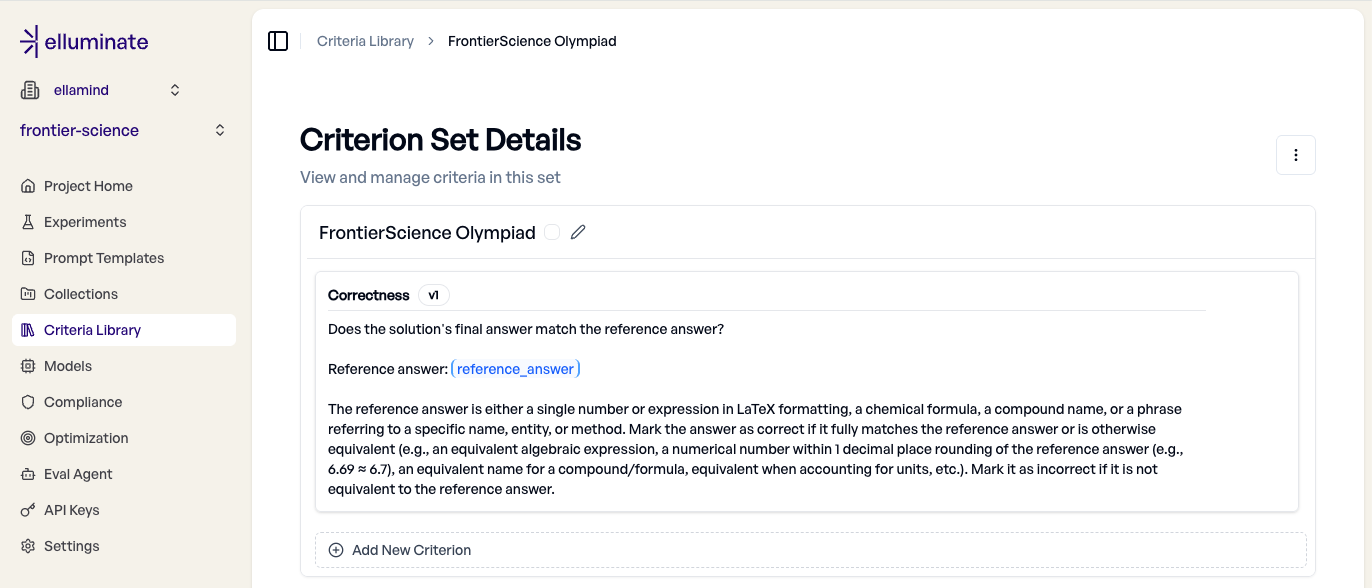
Dieses Kriterium haben wir direkt aus dem Judge-Prompt übernommen, den OpenAI in ihrem Paper veröffentlicht hat[1].
Experimente durchführen
Jetzt können die Experimente starten. Wir übergeben die Aufgabe an den Eval Agent von elluminate, einen in die Plattform integrierten KI-Assistenten, der Experimente aus einem Prompt in natürlicher Sprache anlegen, ausführen und auswerten kann.
Wir haben ihm folgende Anweisung gegeben:
Evaluiere die folgenden Modelle mit reasoning_effort high auf dem FrontierScience-Benchmark. Nutze dafür die bestehende Collection, das Prompt-Template und das Kriterium:
- GPT-5.4
- Claude Opus 4.6
- Gemini 3.1 Pro
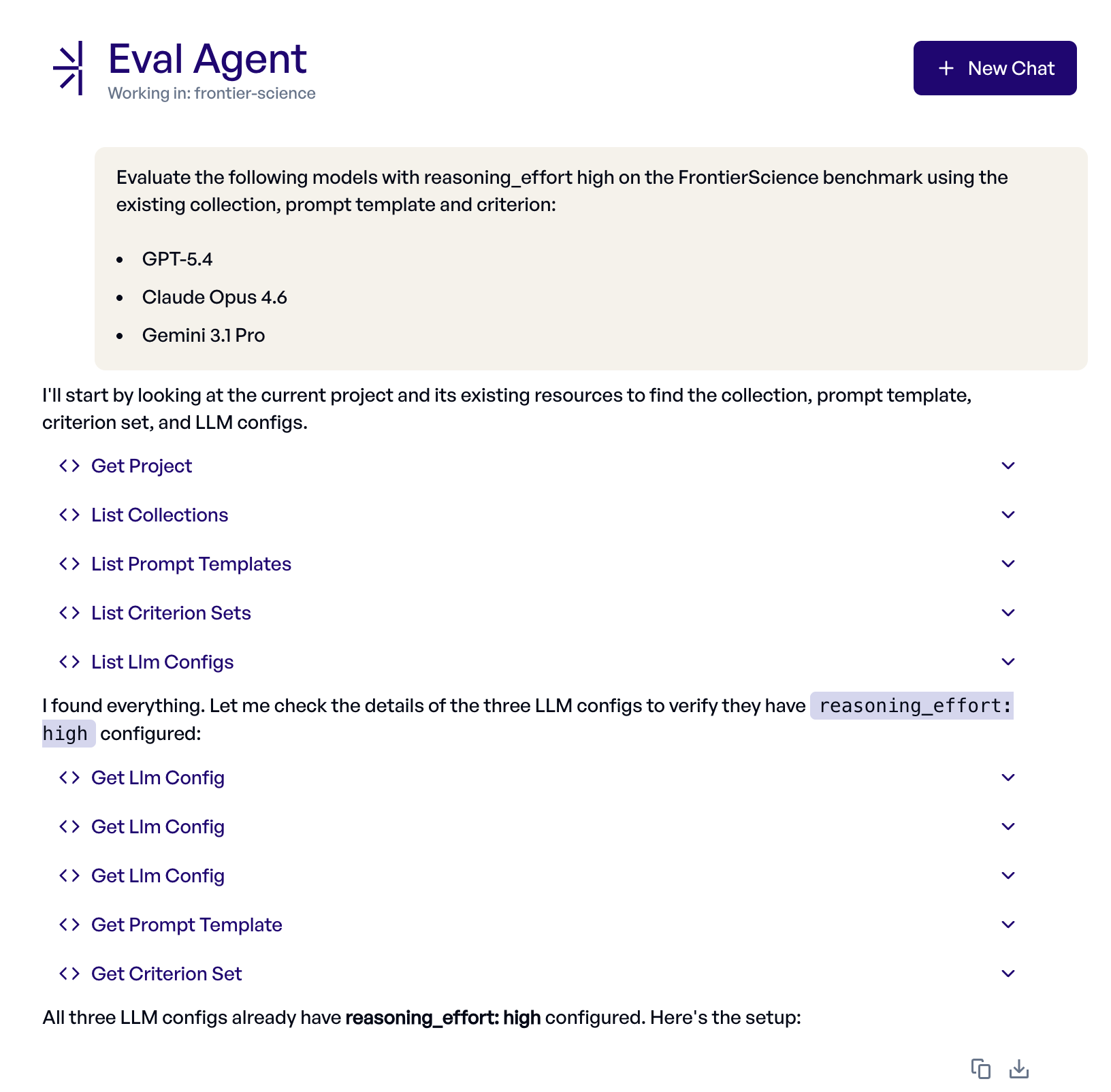
Der Eval Agent legt für jedes der angefragten Modelle ein Experiment an und startet es. Konfiguration und Ausführung übernimmt er selbstständig. Hier sein Trace:

Im Experimente-Dashboard verfolgen wir den Fortschritt:
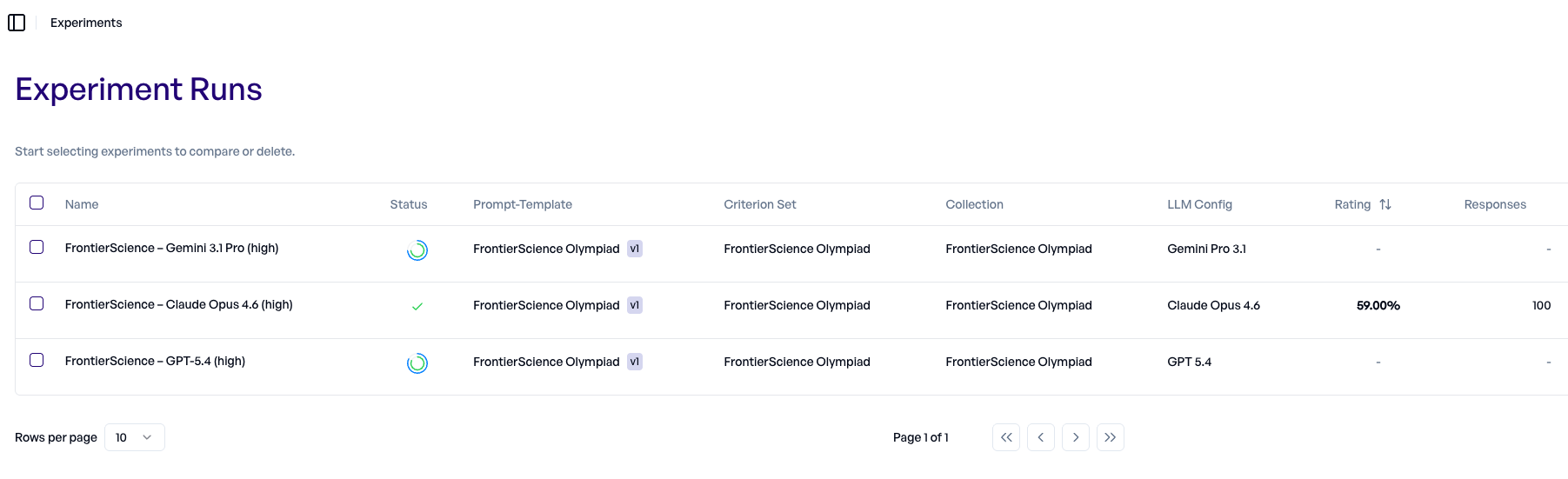
Claude ist bereits fertig, während Gemini 3.1 und GPT 5.4 noch laufen.
Ergebnisse interpretieren
Sobald alle Experimente durchgelaufen sind, bitten wir den Eval Agent um die Analyse:
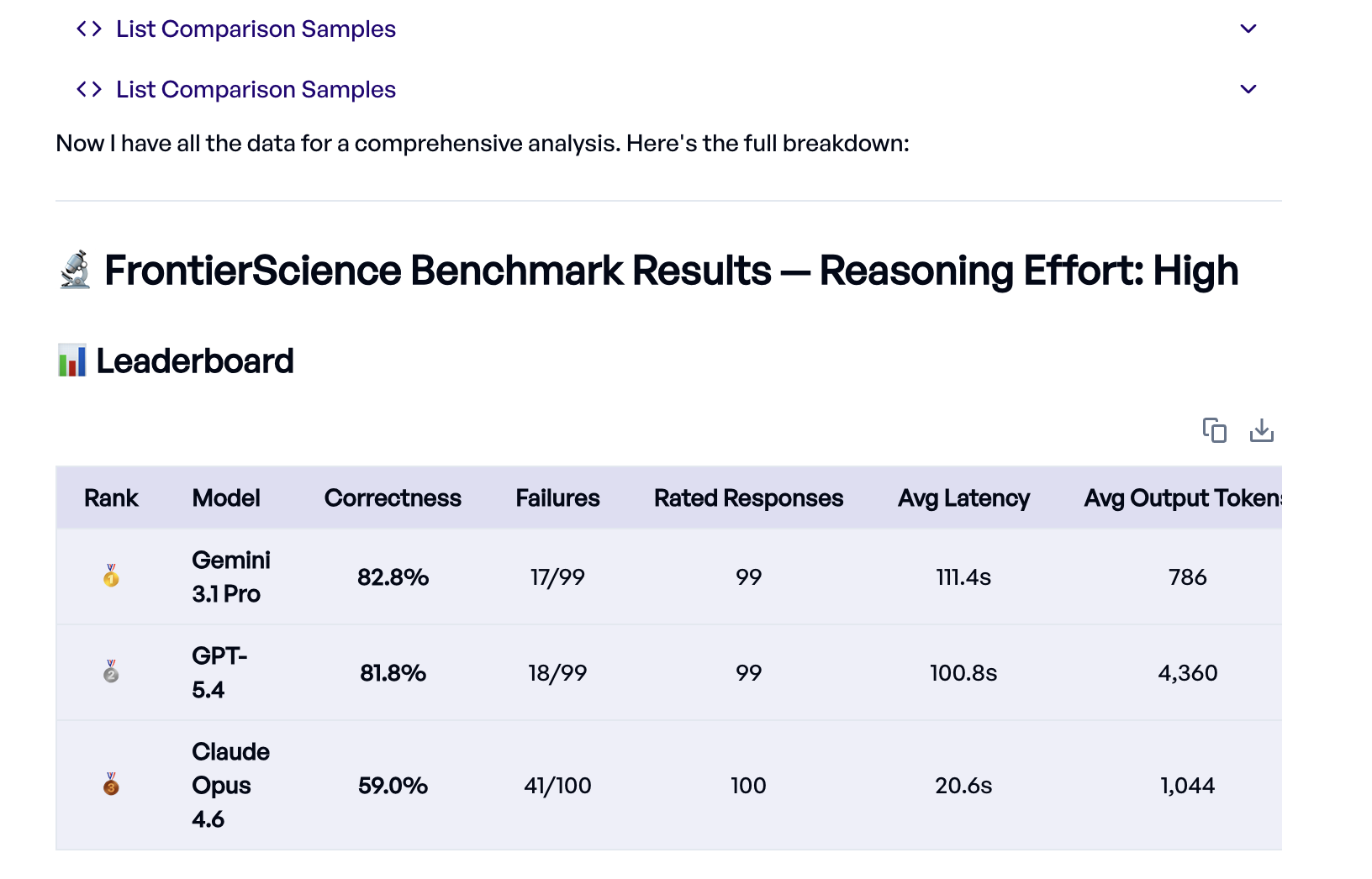
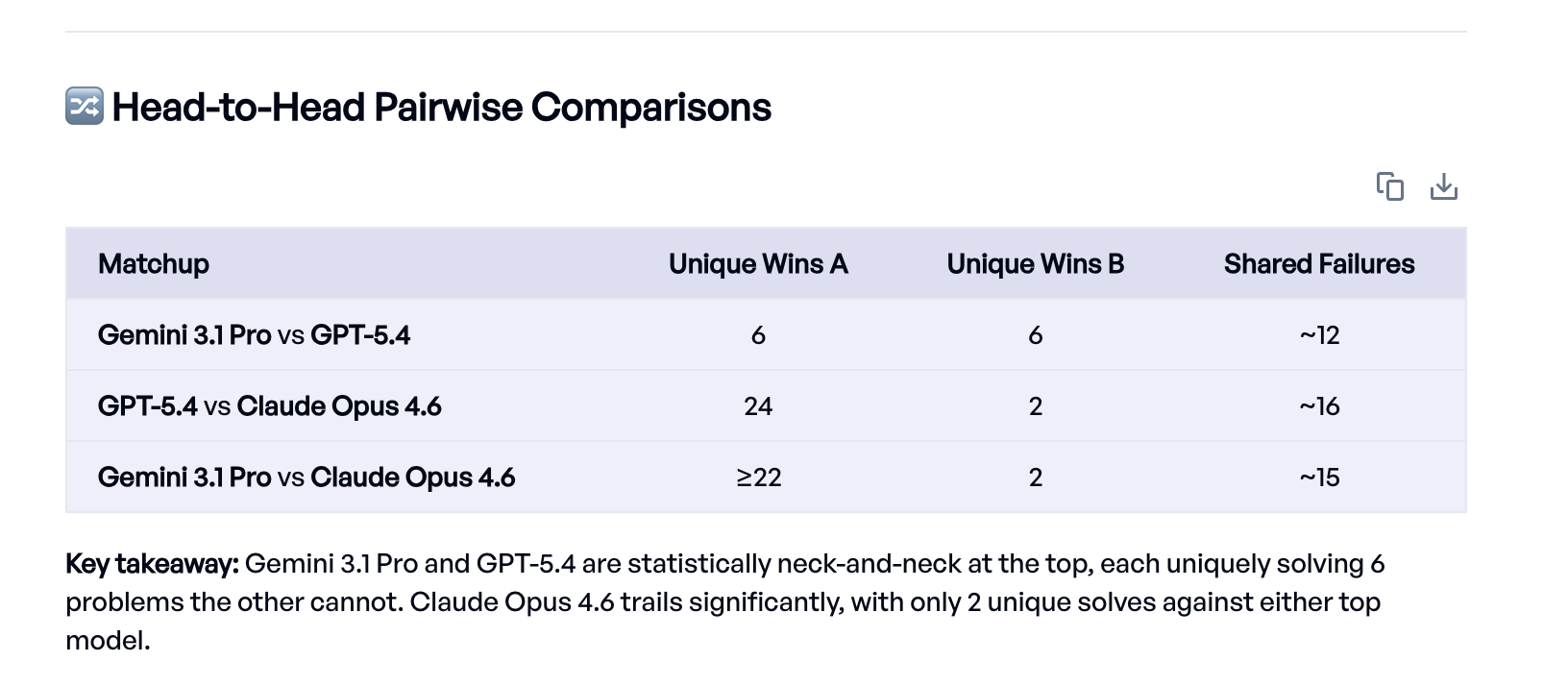
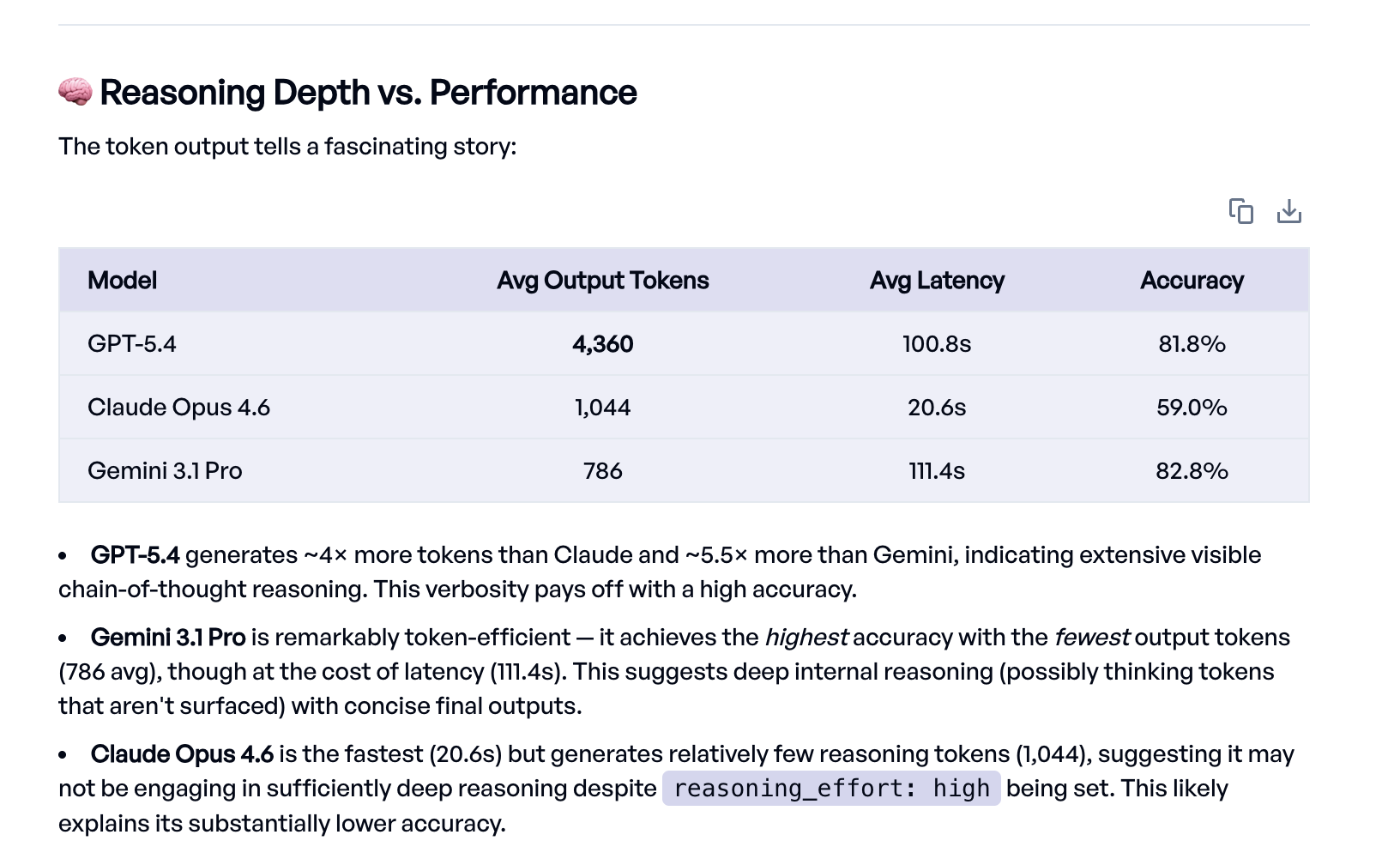


Der Eval Agent ist weit über das bloße Ablesen der Scores hinausgegangen. Er hat die Ergebnisse jedes Experiments abgerufen, paarweise Vergleiche durchgeführt, um Aufgaben zu finden, die das eine Modell löste und das andere nicht, konkrete Fehlerfälle angesehen und typische Fehlermuster wie Vorzeichenfehler und fehlende Terme identifiziert.
Das zentrale Ergebnis: Gemini 3.1 Pro und GPT-5.4 liegen an der Spitze nahezu gleichauf (82,8 % und 81,8 %), während Claude Opus 4.6 mit 59 % zurückbleibt.1
Ein interessantes Detail, das der Eval Agent aufgedeckt hat, ist der Zusammenhang zwischen Ausgabelänge und Genauigkeit. GPT-5.4 erzeugt rund 4.000 Tokens pro Antwort mit umfangreichem, sichtbarem Chain-of-Thought-Reasoning, während Gemini mit unter 800 Tokens eine leicht bessere Genauigkeit erreicht. Claude liefert die kürzesten Antworten und ist mit Abstand am schnellsten, doch die niedrige Token-Zahl deutet darauf hin, dass es bei diesen Aufgaben nicht tief genug schlussfolgert. Ein naheliegender nächster Schritt wäre, den Prompt zu optimieren und Claude zu tieferem Reasoning zu bewegen.
Auswertung nach Fachgebiet
Zusätzlich haben wir den Eval Agent um eine Auswertung nach Fachgebiet gebeten:
| Modell | Physik (50) | Chemie (40) | Biologie (10) |
|---|---|---|---|
| Gemini 3.1 Pro | 80,0 % | 95,0 % | 50,0 % |
| GPT-5.4 | 78,0 % | 95,0 % | 50,0 % |
| Claude Opus 4.6 | 56,0 % | 70,0 % | 30,0 % |
| Durchschnitt über alle Modelle | 71,3 % | 86,6 % | 43,3 % |
Chemie ist nahezu gelöst. Sowohl GPT-5.4 als auch Gemini 3.1 Pro erreichen 95 % und scheitern an jeweils nur 2 Aufgaben.
Physik ist schwieriger, aber mit rund 80 % schon in Sichtweite.
Biologie ist die deutliche Schwachstelle. Keines der Modelle schafft mehr als die Hälfte. Es handelt sich um experimentelle Biologie-Aufgaben (Molekulares Klonen, scRNA-seq, Signalwege), die spezialisiertes Wet-Lab-Wissen voraussetzen. Mit nur 10 Aufgaben im Teilsatz sind die Zahlen mit Vorsicht zu genießen, doch das Schwierigkeitsprofil ist über alle drei Modelle hinweg konsistent.
Claudes Rückstand zieht sich gleichmäßig durch alle drei Fachgebiete, er konzentriert sich nicht auf einen Bereich. Zusammen mit den oben beobachteten kürzeren Ausgaben spricht das für einen systematischen Unterschied in der Reasoning-Tiefe, nicht für eine fachspezifische Schwäche.
Wie es weitergeht
Vor drei Monaten erreichte das beste Modell bei diesen Aufgaben 77 %. Jetzt liegen zwei Modelle über 82 %, und Chemie ist mit 95 % nahezu gelöst. Physik ist in Sichtweite. Die Biologie-Aufgaben bleiben an der Frontier bislang ungelöst. Beim aktuellen Tempo des Fortschritts wahrscheinlich nicht mehr lange.
Mit elluminate sind wir in kürzester Zeit von einem öffentlichen HuggingFace-Datensatz zu einem vollständigen Modellvergleich gelangt. Von hier aus lässt sich die Arbeit in viele Richtungen weiterführen: weitere Modelle evaluieren, das Prompt-Template optimieren, um die Leistung eines bestimmten Modells zu verbessern, oder mehr Durchläufe rechnen, um die Varianz zu senken. Derselbe Workflow greift für jede Evaluation, nicht nur für Science-Benchmarks.
Wenn Sie elluminate selbst ausprobieren möchten, nehmen Sie Kontakt auf — wir helfen Ihnen beim Einstieg. Wir unterstützen alle Arten von Anwendungsfällen, einschließlich agentischer Evaluation.
Literaturverzeichnis
- Wang, M., Lin, R., Hu, K., Jiao, J., Chowdhury, N., Chang, E., & Patwardhan, T. (2026). FrontierScience: Evaluating AI’s Ability to Perform Expert-Level Scientific Tasks. arXiv:2601.21165
- Rein, D., Hou, B. L., Stickland, A. C., Petty, J., Pang, R. Y., Dirani, J., Michael, J., & Bowman, S. R. (2023). GPQA: A Graduate-Level Google-Proof Q&A Benchmark. arXiv:2311.12022





