KI entwickelt sich rasant - Vertrauen hinkt hinterher.
Was ist elluminate?
Überall experimentieren Teams mit großen Sprachmodellen. Ohne systematische Evaluation bleiben die Ergebnisse jedoch unvorhersehbar, uneinheitlich und schwer zu rechtfertigen. Ob Sie an Prompts feilen, kundenseitige Chatbots ausrollen oder KI im Produktivbetrieb überwachen: Vermutungen reichen nicht aus.
Genau dafür haben wir elluminate gebaut.
elluminate macht aus einem chaotischen, manuellen Prozess ein strukturiertes System. Mit elluminate können Sie:
- Prompts systematisch testen, bevor sie in die Produktion gehen
- Klare Erfolgskriterien definieren und die Leistung objektiv messen
- Edge Cases und Fehlerbilder frühzeitig erkennen
- Produktivanwendungen überwachen und stille Regressionen aufspüren, bevor es Ihre Nutzer tun
Das Ergebnis? Zuverlässige, messbare und produktionsbereite KI.
In diesem Einstiegs-Guide führen wir Sie durch die Grundlagen der Arbeit mit elluminate. Anhand eines verspielten Beispiels rund um Pizzabeläge zeigen wir, wie Evaluationen in der Praxis funktionieren. Hinter dem Spaß steckt ein ernster Kern: Evaluationen sind das Fundament vertrauenswürdiger Systeme - und elluminate ist die Entscheidungsebene für zuverlässige KI.
Warum Evaluation entscheidend ist
Die meisten KI-Teams kennen dasselbe Problem: In der Demo sieht das Modell glänzend aus, in der Produktion bricht es auseinander. Der Grund: Evaluation läuft informell ab - ein paar Stichproben hier, manuelle Durchsichten da, und viel „scheint zu funktionieren”. Aus diesem Ratespiel entstehen drei große Risiken:
- Inkonsistenz: Prompts oder Modelle verhalten sich je nach Anwendungsfall unterschiedlich, ohne dass sich nachvollziehen lässt, warum.
- Blinde Flecken: Edge Cases bleiben unentdeckt, bis sie auf echte Nutzer treffen.
- Fehlender Nachweis: Ohne messbare Erfolgskriterien lässt sich die Leistung weder gegenüber Stakeholdern noch gegenüber Kunden oder Aufsichtsbehörden belegen.
elluminate löst das mit den Bausteinen systematischer Evaluation:
- Prompt-Templates: Schluss mit Copy-Paste, her mit Versionierung. Templates machen Prompts wiederverwendbar und messbar.
- Collections: Testdatensätze, die reale Beispiele mit Edge Cases mischen, damit Fehler früh sichtbar werden - nicht erst in der Produktion.
- Kriterien: binäre Ja/Nein-Erfolgsmaße. Kein „passt schon” mehr; jede Antwort wird objektiv bewertet.
- LLM-Konfigurationen: Führen Sie Evaluationen mit denselben Modelleinstellungen durch wie im Produktivbetrieb, damit die Ergebnisse die Realität abbilden.
- Experimente: Alles in einem: Prompts + Daten + Kriterien + Modelle = messbare Leistung.
Gemeinsam machen diese Bausteine aus Evaluation einen wiederholbaren Prozess, auf den Sie sich verlassen können.
Schritt 1: Prompt-Templates
Das Problem: Prompts entstehen ad hoc, werden endlos angepasst und gehen im Versionschaos schnell verloren. Teams können nicht mehr nachvollziehen, was funktioniert hat - und warum.
Die Lösung in elluminate: Prompt-Templates geben dem Prozess Struktur. Ein Template ist wiederverwendbar und versioniert. Statt dieselbe Frage immer wieder neu zu formulieren, bauen Sie eine flexible Struktur mit Platzhaltern. Jede Iteration wird automatisch protokolliert; der Kontext früherer Tests bleibt erhalten.
Pizza-Experiment: Anstatt „Gehört Ananas auf Pizza?” und danach „Was ist mit Pilzen?” immer wieder ins Playground zu kopieren, erstellen Sie ein einziges Template:

Der Platzhalter {{ingredient}} nimmt jeden Wert aus Ihrem Datensatz an. So testen Sie Dutzende Beläge konsistent und halten das Ausgabeformat stabil.
Im Lauf der Zeit zeigt elluminate, wie sich Template-Versionen entwickeln - Iteration wird nachvollziehbar.
Schritt 2: Collections
Das Problem: Die meisten Teams testen Prompts nur mit ein paar „Happy-Path”-Beispielen. In der Demo sieht das gut aus, doch sobald ein Nutzer etwas Schräges fragt, bricht das System. Ohne systematische Testdaten bleiben blinde Flecken verborgen, bis sie in die Produktion durchschlagen.
Die Lösung in elluminate: Collections sind strukturierte Datensätze, die in Ihre Templates einfließen. Sie mischen saubere Beispiele, Grenzfälle und adversariale „Trick”-Fälle, sodass Sie Stärken und Schwächen früh sehen. Statt nur das Erwartete zu testen, tasten Sie gezielt die Ränder ab.
Pizza-Experiment: Eine solide Collection könnte enthalten:
- Klare Fälle: Mozzarella, Pepperoni, Pilze.
- Kontroverse Fälle: Ananas, Sardellen.
- Dessert-Überraschungen: Schokoladenstücke, Eiscreme.
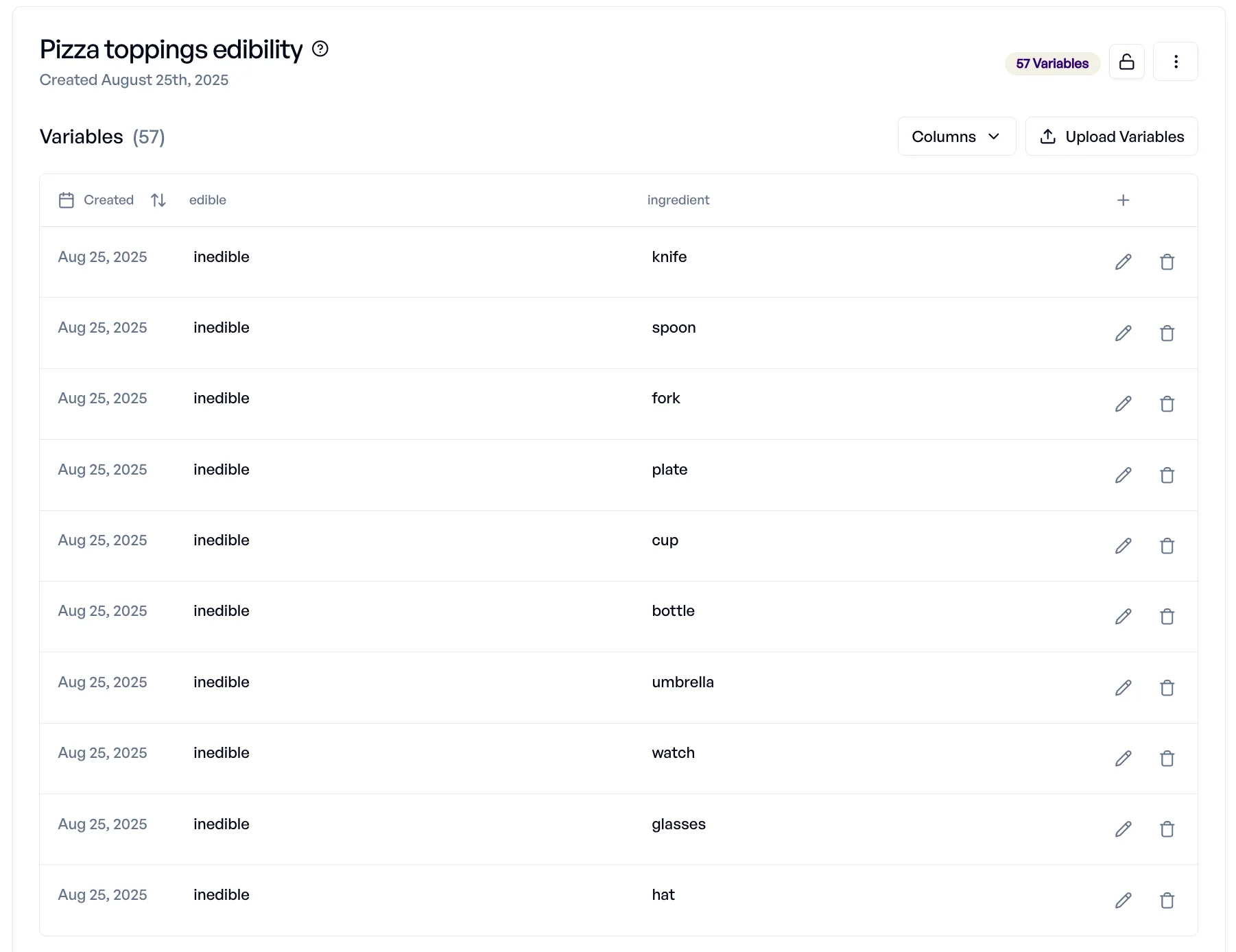
- Adversariale Nicht-Lebensmittel: Löffel, Plastik, Motoröl.
Wenn Sie Ihr Template gegen diese Bandbreite laufen lassen, erfahren Sie mehr als nur „der Prompt funktioniert”. Sie erfahren, wo er scheitert: Lässt sich das Modell von kulturell umstrittenen Belägen verwirren, klassifiziert es Desserts falsch oder übersieht es offensichtlich Ungenießbares? Genau diese Praxis - Edge Cases bewusst einzubauen - macht elluminate-Evaluationen produktionsreif.
Schritt 3: Kriterien
Das Problem: Selbst mit guten Testdaten tappen viele Teams in die Falle subjektiver Bewertung. Ein Reviewer sagt „gut genug”, ein anderer widerspricht. Oder noch schlimmer: Kriterien sind so vage formuliert („Ist die Antwort korrekt?”), dass niemand sie konsistent messen kann. Ohne objektive Kriterien lassen sich Durchläufe nicht vergleichen - und Fortschritt ist nicht belegbar.
Die Lösung in elluminate: In elluminate ist jedes Evaluationskriterium binär - Pass oder Fail. Das erzwingt Klarheit. Statt Bauchgefühl treffen Sie klare Ja/Nein-Prüfungen. Ergänzen Sie Ihre Collections um „Golden Answers”, und die Ergebnisse werden automatisch gegen Ihre Ground Truth bewertet.
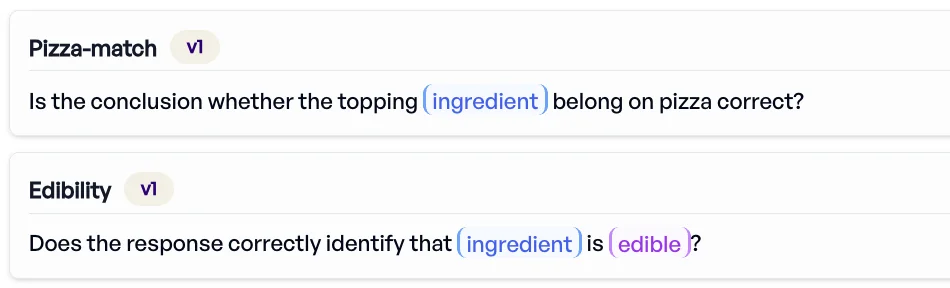
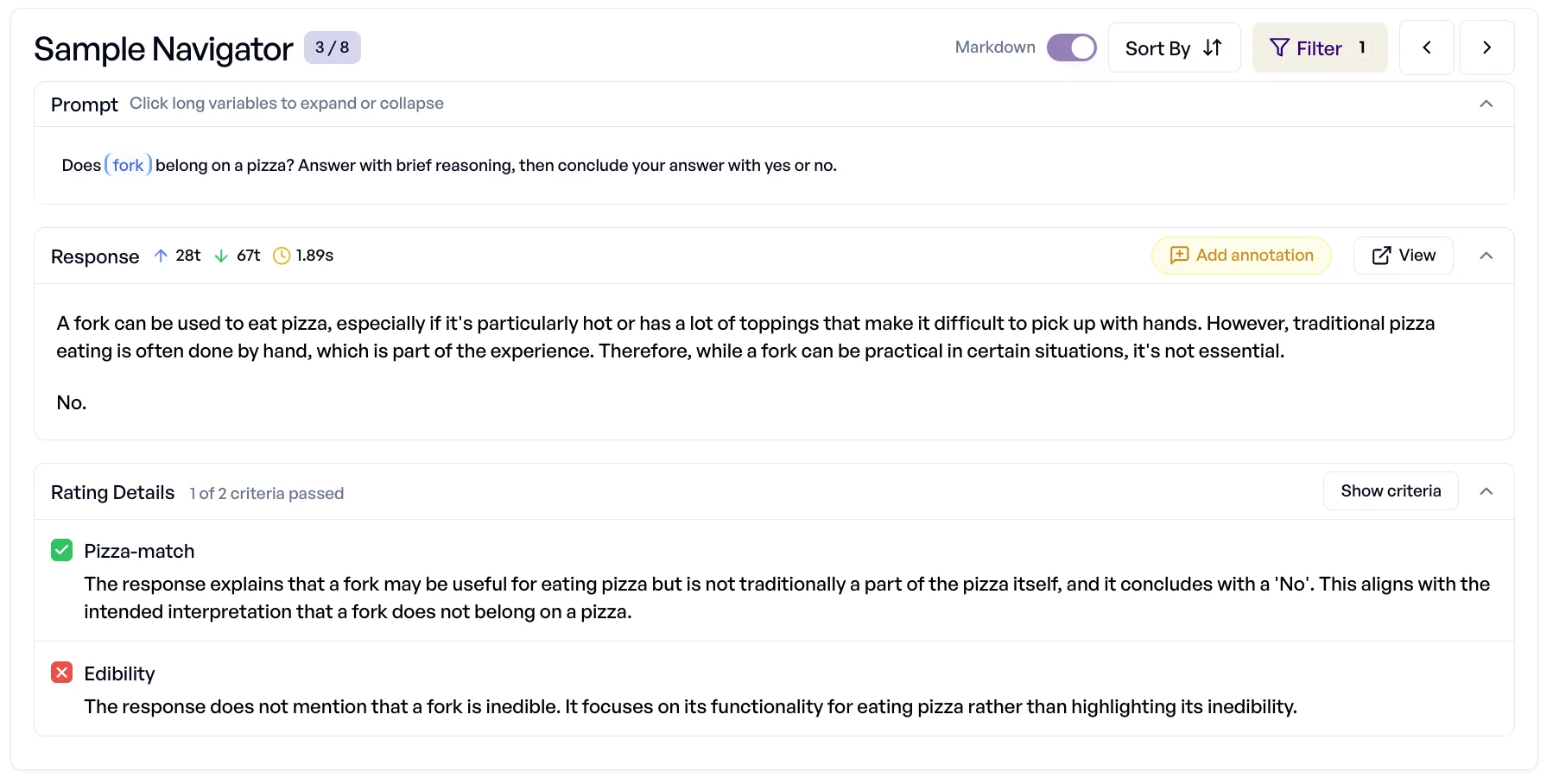
Pizza-Experiment: Angenommen, Sie legen ein Kriterium an: „Ist die Zutat essbar? Gehört der Belag auf eine Pizza?”
Das sind zwei Fragen in einer - und macht die Auswertung unklar. Ein Modell könnte korrekt sagen „Motoröl gehört nicht auf Pizza” und dennoch übersehen, dass es nicht essbar ist.
Die Lösung: Kriterien aufteilen.
- Essbarkeit: „Ist die Zutat essbar?”
- Pizza-Eignung: „Gehört die Zutat auf eine Pizza?”
Jetzt reichern Sie Ihre Collection mit Labels zur Essbarkeit an („essbar” / „nicht essbar”) und vergleichen die Modellausgaben gegen die Ground Truth. Das liefert aufschlussreiche Erkenntnisse: Sie sehen, ob das Modell bei Lebensmittelsicherheit, bei Auslassungen oder beim kulturellen Verständnis rund um Pizzabeläge schwächelt.
Schritt 4: Das richtige Modell wählen
Das Problem: Teams greifen oft reflexartig zum größten, teuersten Modell - in der Annahme, „leistungsfähiger” heiße „besser”. In Wahrheit verhalten sich Modelle sehr unterschiedlich: Manche sind schnell, aber oberflächlich, andere nuanciert, aber teuer, wieder andere für sehr spezifische Aufgaben feingetunt. Ohne belastbaren Vergleich riskieren Sie hohe Kosten oder das falsche Werkzeug für den Job.
Die Lösung in elluminate: elluminate erlaubt es, mehrere LLMs direkt nebeneinander zu konfigurieren und zu vergleichen. Sie testen kleine gegen große Modelle, generelle gegen domänenspezialisierte - und messen, wie jedes gegen denselben Datensatz und dieselben Kriterien abschneidet. Statt zu raten, sehen Sie genau, welches Modell zu Ihrem Anwendungsfall passt.
Pizza-Beispiel:
- Ein kleines, schnelles Modell trifft vielleicht 95 % der Beläge richtig - zu einem Bruchteil der Kosten. Ideal für hochvolumige Klassifikation.
- Ein größeres Reasoning-Modell erkennt womöglich Feinheiten („Eiscreme könnte auf eine Dessert-Pizza passen”) und zeigt tieferes Kontextverständnis.
- Ein auf Lebensmittel feingetuntes Spezialmodell schlägt unter Umständen beide - wenn Ihre Domäne eng genug ist.
Es geht nicht darum, einen universellen Sieger zu küren. Es geht um die richtige Balance aus Geschwindigkeit, Kosten und Genauigkeit für Ihre Anwendung. Mit elluminate belegen Sie, welches Modell am besten abschneidet - statt sich auf den Hype zu verlassen.
Schritt 5: Experimente ausführen und Ergebnisse deuten
Das Problem: Rohe Scores können in die Irre führen. Ein Modell, das auf den ersten Blick glänzt (etwa mit 90 % Genauigkeit), kann gravierende blinde Flecken verbergen. Ohne die Ergebnisse aufzuschlüsseln, wissen Sie nicht, wo es scheitert, warum es scheitert und ob diese Fehler in der Produktion ins Gewicht fallen.
Die Lösung in elluminate: elluminate liefert nicht nur eine Zahl, sondern mehrere Ebenen Erkenntnis:
- Gesamt-Score: eine schnelle Übersicht der Genauigkeit.
- Kriterien-Leistung: sehen Sie, ob das Modell bei „Essbarkeit” oder „Pizza-Eignung” schwächelt.
- Fehlerfälle: tauchen Sie in konkrete Beispiele ein, bei denen das Modell pro Kriterium danebenlag.
- Konsistenz über Durchläufe hinweg: vergleichen Sie, wie stabil das Modell über wiederholte Experimente oder Epochen bleibt.
Pizza-Experiment: Ihr Baseline-Experiment zeigt:
- 89,5 % Erfolgsrate im Gesamt-Score
- 93 % Erfolgsrate bei „Gehört es auf Pizza?”
- 86 % Erfolgsrate bei „Ist es essbar?”.
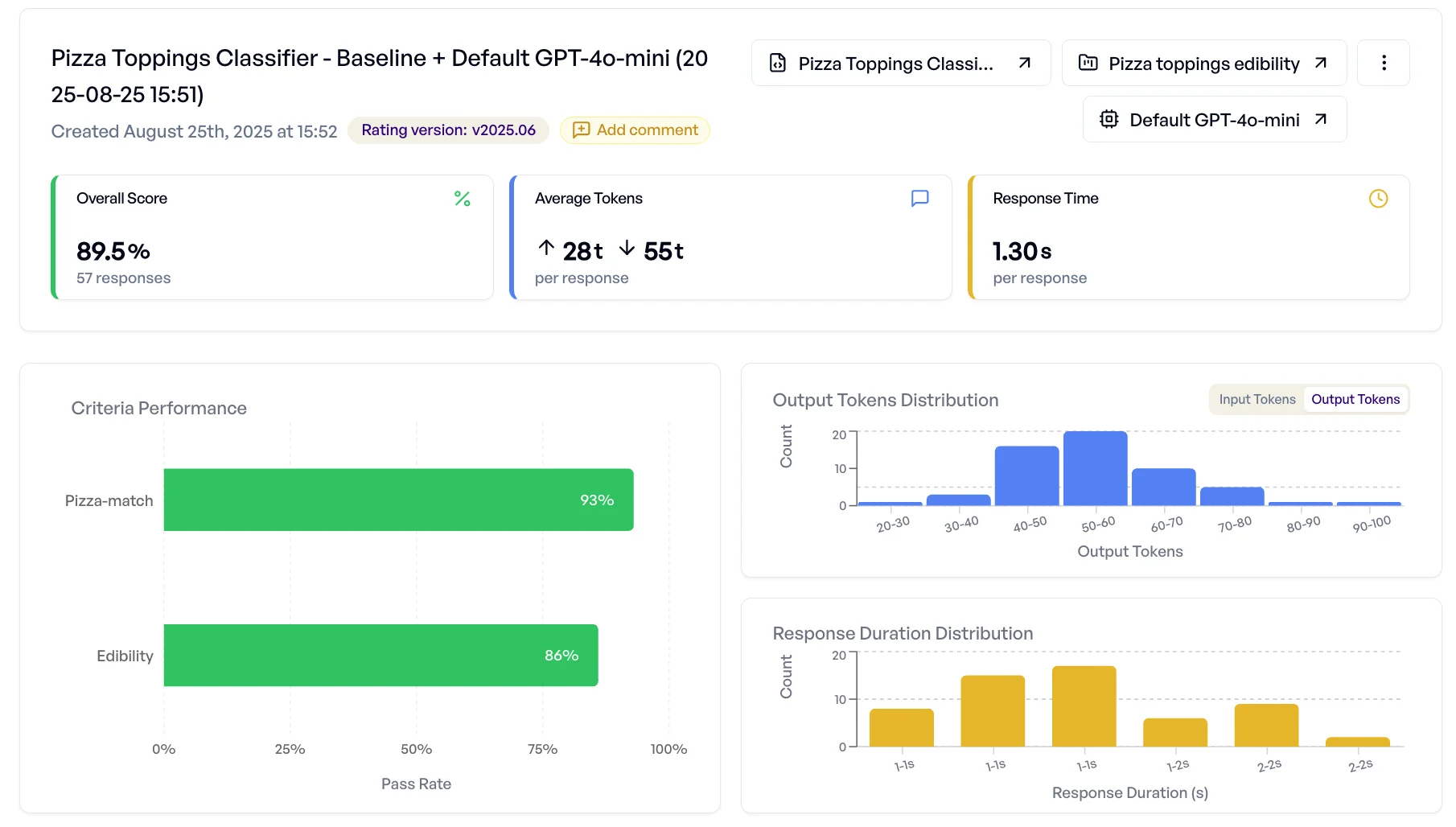
Auf den ersten Blick wirken 89,5 % solide. Beim Hineinschauen zeigt sich jedoch: Das Modell klassifiziert Schokoladenstücke als „nicht essbar” und trennt Besteck manchmal nicht sauber vom Essen. Das sind keine zufälligen Ausrutscher - sie können auf systematische Schwächen hindeuten.
Wenn Sie Fehler direkt in elluminate analysieren, verstehen Sie die Nuancen falscher Antworten. Genau das ist der Unterschied zwischen anekdotischen Tests („bei mir lief’s”) und systematischer Evaluation („hier scheitert es - und so lässt es sich beheben”).
Schritt 6: Iteration & Verbesserung
Das Problem: Teams jagen Fehlern oft blind hinterher. Sie fügen mehr Daten hinzu, schrauben am Prompt oder tauschen Modelle - ohne zu wissen, ob sie die Ursache treffen. Iteration verkommt zu Trial-and-Error, ganz ohne Strategie.
Die Lösung in elluminate: Iteration ist in elluminate nachvollziehbar. Jeder Fehlerfall wird protokolliert. Jeder Score zeigt, ob das Problem an der Prompt-Klarheit, an den Modelleinstellungen oder am Kriterien-Design liegt. So werden Verbesserungen gezielt statt zufällig.
Pizza-Experiment:
- Wenn die Formattreue scheitert (das Modell liefert Aufsätze statt „Ja/Nein”), wissen Sie, dass Sie zuerst Ihre Prompt-Anweisungen schärfen müssen.
- Wenn Desserts immer wieder als ungenießbar markiert werden, liegt das Problem womöglich bei Ihren Kriterien oder Labels - nicht beim Modell.
- Wenn die Ergebnisse bei „Pepperoni” stark schwanken, ist Ihre Temperature zu hoch, oder das Modell reasont zu viel.
Entscheidend ist zu erkennen, wann „gut genug” erreicht ist. Mit 95 % Genauigkeit und einem klaren Verständnis der verbleibenden 5 % sind Sie produktionsbereit. Perfektion ist eine Falle - selbst Menschen streiten darüber, ob Mayonnaise auf die Pizza gehört.
Die Entscheidungsebene für zuverlässige KI
Wir haben Pizzabeläge genutzt, um zu zeigen, wie elluminate funktioniert - doch im KI-Alltag stehen deutlich größere Werte auf dem Spiel. Für Unternehmen sind die Probleme klar:
- Compliance-Risiko: In regulierten Branchen lässt sich KI nicht ausliefern, ohne die Einhaltung von Standards nachzuweisen.
- Kundenerlebnis: Eine einzige schlechte Chatbot-Antwort zerstört Vertrauen sofort.
- Betriebskosten: Händisches Testen skaliert nicht, und das Hinterherjagen von Fehlern frisst Wochen.
- Lähmung bei der Modellwahl: Ohne systematische Vergleiche zahlen Sie entweder für große Modelle drauf oder pokern mit kleinen.
elluminate löst diese Probleme, indem es Evaluation wiederholbar, messbar und belastbar macht. Ob Sie interne Copilots bauen, kundenseitige Assistenten oder automatisierte Dokument-Workflows: elluminate gibt Ihnen die Sicherheit, dass sich Ihre KI auch unter Druck konsistent verhält.
Der Unterschied ist einfach: Ohne Evaluationen bleibt KI unvorhersehbar. Mit elluminate wird KI zuverlässig, auditierbar und produktionsbereit.
Und Sie müssen das nicht allein herausfinden. Unsere Gründer arbeiten direkt mit frühen Kunden zusammen und entwerfen Evaluierungsstrategien passgenau für deren Systeme - von der Prompt-Iteration bis zum Live-Monitoring.
Bereit, Ihre KI zuverlässig zu machen?
Buchen Sie eine private Demo mit unseren Gründern und erleben Sie, wie elluminate Ihren Workflow verändert.





