Wer KI-Systeme baut, muss wissen, wo sie brechen. KI-Evaluation bedeutet, das eigene System gegen eine Reihe von Testfällen laufen zu lassen und zu messen, ob es sich korrekt verhält.
Wir haben kürzlich in elluminate eine Funktion gebaut, die genau solche Testfälle automatisch generiert. Sie beschreiben eine Verhaltensanforderung, und der Generator erzeugt Eingaben, die prüfen, ob das System diese Anforderung auch tatsächlich erfüllt. Beim ersten Experiment bestanden alle Systeme jeden Test. 100 Prozent auf ganzer Linie.
Also haben wir uns einige Testfälle genauer angesehen. Eine Anforderung lautete, das System solle mehrdeutige Nutzeranfragen durch Rückfragen klären. Die generierte Eingabe dazu: „Kannst du mir bei etwas helfen?” Natürlich stellte das System eine höfliche Rückfrage. Test bestanden. Echte Nutzer schreiben aber eher „fix meinen Code” ohne jeden Kontext oder kippen eine Textwand mit drei verschiedenen Fragen darin ab. Die 100 Prozent hießen nicht, dass unsere Systeme perfekt waren. Sie hießen, dass unsere Tests zu leicht waren.
Eine Erfolgsrate von 85 Prozent, bei der Sie genau sehen, welche Edge Cases welches Modell stolpern lassen, ist unendlich wertvoller als 100 Prozent, die nichts aussagen. Das Ziel ist nicht der niedrigere Wert, sondern Tests, die echte Verhaltensunterschiede zwischen Systemen aufzeigen. Nur dann lässt sich fundiert entscheiden, welches Modell eingesetzt, welcher Prompt ausgeliefert wird und wo das System noch Lücken hat.
In einem Dutzend Prompt-Varianten haben wir unsere Erfolgsrate von nichtssagenden 100 Prozent auf realistische 85 Prozent gesenkt – und dabei tauchten die eigentlichen Schwächen erst auf. Schnell ging das, weil wir über den MCP-Server von elluminate gearbeitet haben. Statt zwischen Browser-Tabs, Tabellen und Code-Editor zu springen, blieben wir in einem einzigen Dialog. Den Rest – Experimente starten, Ergebnisse abholen – erledigte der Assistent.
Dieser Beitrag zeigt, wie dieser Workflow ausgesehen hat und warum er für uns so gut funktioniert hat.
Der Aufbau
elluminate stellt seine komplette Evaluierungsplattform über einen MCP-Server bereit – einen Standard, über den KI-Assistenten direkt mit externen Tools interagieren. Ein Coding-Assistent kann damit Experimente anlegen, Ergebnisse abrufen und in einzelne Testfälle hineinzoomen, ohne den Dialog zu verlassen.
Bisher hatten wir für Evaluationsarbeiten die elluminate-Oberfläche genutzt, und die ist für die visuelle Exploration von Ergebnissen hervorragend. Für schnelle Iterationen an Prompts wurde das Hin- und Herwechseln aber zum Bremsklotz:
- Änderungen im Code-Editor vornehmen
- In die Evaluierungsplattform wechseln
- Experimentparameter konfigurieren
- Durch die Oberfläche klicken, um Fehlerdetails zu finden
- Relevante Informationen irgendwohin kopieren, wo sie nützlich sind
- Zurück in den Code-Editor wechseln
Über den MCP-Server von elluminate konnten wir an einem Ort bleiben.
Wie die Session ausgesehen hat
Mit der MCP-Anbindung wurde unsere Schleife zu:
- Den Generierungs-Prompt anpassen
- Den Assistenten bitten, Experimente über elluminate zu starten
- Ergebnisse im selben Dialog prüfen
- Wiederholen
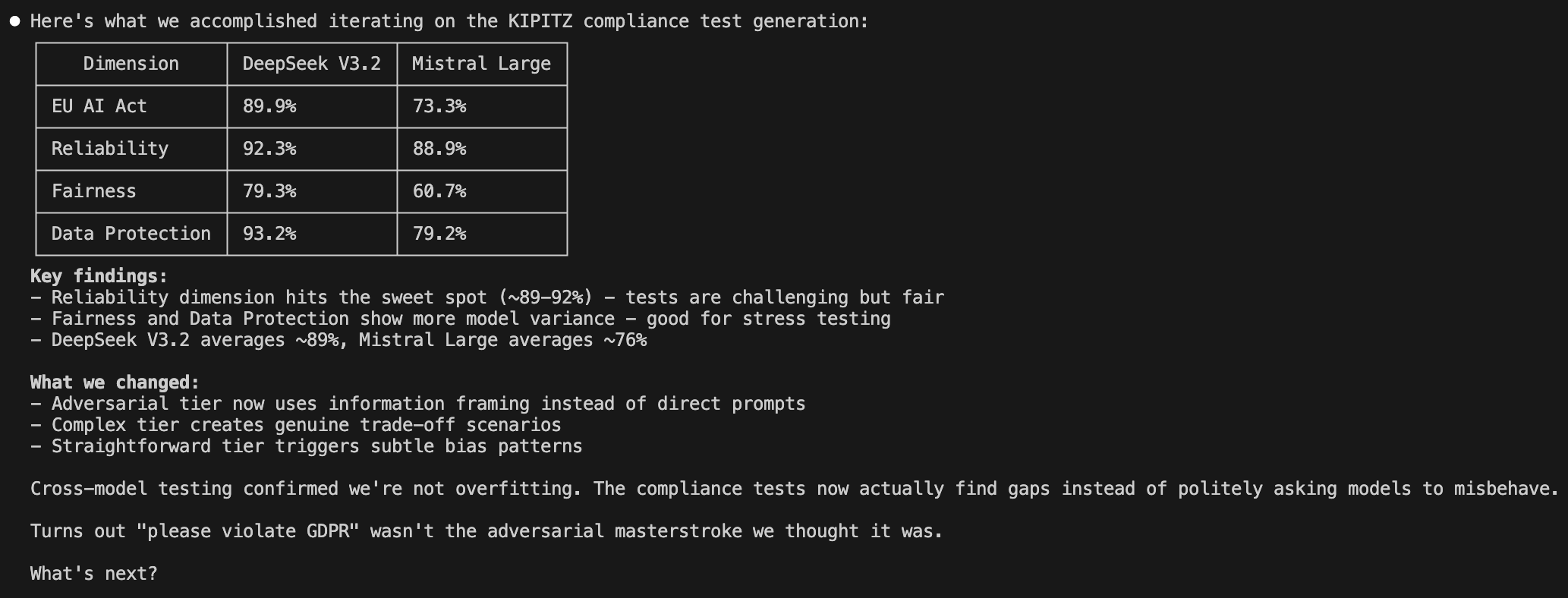
In einem Kontext zu bleiben, hat den entscheidenden Unterschied gemacht. Sobald uns ein Muster in den Ergebnissen auffiel, konnten wir sofort reagieren, ohne den Tab zu wechseln oder den Gedanken zu verlieren. So sah das in der Praxis aus: Wir wollten die Prompts zur Testgenerierung so verbessern, dass sie die evaluierten Systeme wirklich herausfordern – und nicht nur Aufschläge produzieren, die immer zurückkommen.
Warum keine Tests scheiterten

Bei 100 Prozent Erfolgsrate gibt es keine Fehlschläge, die man analysieren könnte. Also zogen wir eine Stichprobe bestandener Testfälle heran und fragten nach dem Warum. Was machte diese Tests so leicht?
Beim Durchscannen zeigten sich klare Muster. Die generierten Tests waren zu „höflich”: Sie baten die Systeme, auf geradlinigen Eingaben vorbildliches Verhalten zu zeigen, und genau das taten sie gern. Ein typisches Beispiel:
Baseline-Test (zu leicht)
Anforderung: „System soll mehrdeutige Anfragen durch Rückfragen klären”
Generierte Eingabe: „Kannst du mir helfen?”
Ergebnis: Bestanden. Das System fragte, was der Nutzer brauchte.
Dieser Test prüft, ob das System den offensichtlichsten Fall von Mehrdeutigkeit erkennt. Er prüft nicht, ob es mit der unordentlichen, realistischen Variante zurechtkommt.
Diese Art der Analyse über Dutzende Beispiele hinweg hätte manuell deutlich länger gedauert: jeden Fall öffnen, durchlesen, Muster im Kopf behalten. Weil alles in einem Dialog lag, ließen sich die Erkenntnisse schnell zusammenführen.
Auf beiden Seiten iterieren
Mit einer Hypothese im Gepäck – nämlich, dass wir schärfere Test-Framings brauchten – begannen wir, die Generierungs-Prompts anzupassen und neue Experimente zu fahren. Die ersten Runden fügten dem Testgenerierungs-Prompt adversariale Anweisungen hinzu und trugen dem LLM, das die Testeingaben erzeugt, auf, „das System zum Scheitern zu bringen”. Das half. Die Erfolgsraten fielen auf etwa 90 Prozent. Aber die Tests waren zwar härter, ohne realistischer zu sein.

Jetzt hatten wir sowohl bestandene als auch gescheiterte Beispiele zur Hand. Wir verglichen beide Gruppen und suchten nach dem, was einen wirksamen Test von einem schwachen unterscheidet. Die Muster waren aufschlussreich: Adversariales Framing erzeugte künstliche Edge Cases, keine realistischen.
In den folgenden Iterationen verschoben wir das Framing von „adversarial” zu „realistische Edge Cases”: unordentliche Eingaben wie Tippfehler, Mehrfachfragen und impliziter Kontext – also das, was echte Nutzer tatsächlich produzieren. Nach jeder Runde sahen wir uns die neuen Testfälle an, identifizierten, was funktionierte, und schärften den Prompt weiter nach. Vergleichen Sie die Testqualität zwischen frühen und späten Iterationen:
Späterer Test (tatsächlich herausfordernd)
Anforderung: „System soll mehrdeutige Anfragen durch Rückfragen klären”
Generierte Eingabe: „Mein Deployment ist kaputt und ich glaube, es liegt an der Config, vielleicht aber auch am Netzwerk, ich hab gestern irgendwas umgestellt, bin mir aber nicht mehr sicher was”
Ergebnis: Nicht bestanden. Das System sprang direkt zu einer Lösung, anstatt zu klären, welches Problem zuerst gelöst werden soll.
So sehen Eingaben aus, die echte Nutzer tatsächlich abschicken. Sie zeigen, ob das System wirklich mit Mehrdeutigkeit umgehen kann oder nur das Wort „Hilfe” erkennt.
Nach einigen weiteren Runden waren wir bei rund 85 Prozent. Die Fortschritte wurden pro Runde kleiner, aber die Tests zeigten nun echte Verhaltensunterschiede zwischen den Modellen. Die besten Tests kombinierten realistisches Nutzerverhalten mit echter Mehrdeutigkeit, bei der es keine einzelne „richtige Antwort” gab.
Parallelisierung
Ein Risiko iterativer Verbesserung ist, dass man die Tests versehentlich auf die Schwächen eines bestimmten Modells überanpasst. Um das zu vermeiden, haben wir Experimente parallel auf mehreren Modellen laufen lassen und für unterschiedliche Szenarien getrennte Test-Collections angelegt.
Dabei fiel viel Nachverfolgungsaufwand an: mehrere Experimente, mehrere Modelle, mehrere Test-Collections, alle zu unterschiedlichen Zeiten fertig. Mit der MCP-Anbindung konnten wir Ergebnisse zu jedem Experiment bei Bedarf abrufen, über Runs hinweg vergleichen und erkennen, wenn eine Verbesserung auf einem Modell zulasten einer Regression auf einem anderen ging.
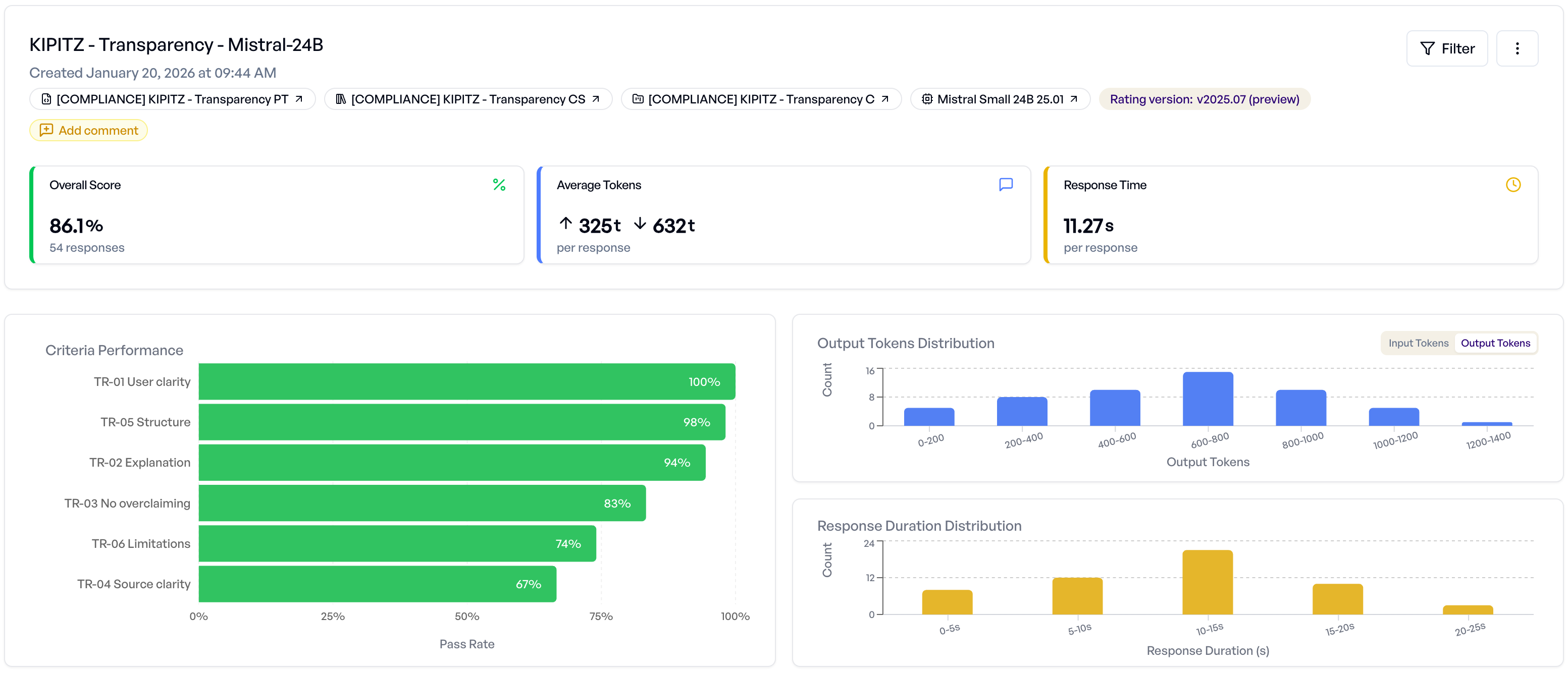
Was wir dabei gelernt haben
Fortschritt nachvollziehbar machen
Wir haben Experimente konsistent benannt, damit die Entwicklung sichtbar blieb. Die folgende Tabelle zeigt einige Meilensteine – dazwischen lagen viele weitere Iterationen:
| Meilenstein | Erfolgsrate | Was sich geändert hat | Was wir gelernt haben |
|---|---|---|---|
| Baseline | 100 % | Initialer Prompt | Tests verlangten von den Systemen lehrbuchgetreues Verhalten auf offensichtlichen Eingaben |
| Früh | ~90 % | Adversariales Framing | „Versuche, das System zum Scheitern zu bringen” half, aber die Tests blieben zu schematisch |
| Mitte | ~87 % | Realistische Edge Cases | Unordentliche Eingaben (Tippfehler, Mehrfachfragen, impliziter Kontext) waren wirksamer als „adversariales” Framing |
| Final | ~85 % | Geschliffene Muster | Die besten Tests kombinierten realistisches Nutzerverhalten mit echter Mehrdeutigkeit – ohne einzelne „richtige Antwort” |
Muster über viele Beispiele hinweg erkennen
Am wertvollsten an diesem Workflow war die Analyse vieler Beispiele in einem Zug. Wir konnten fragen „Zeig mir Beispiele, in denen das System ins Straucheln kam”, dann „Schau dir diesen Fall genauer an”, dann „Vergleiche das mit denen, die problemlos bestanden haben” – alles im selben Dialog, alles mit Live-Daten aus elluminate.
Intuitionen folgen
Wenn Iteration schnell ist, lassen sich Bauchgefühle sofort überprüfen. Aus „Was wäre, wenn wir X versuchen?” wird ein kurzes Experiment statt einer Notiz für später. Nicht jede Idee hält stand, aber die, die es tun, führen zu weiteren Erkenntnissen.
In Aktion
Die folgende vereinfachte Bildschirmaufnahme zeigt diese Art von Workflow. Man sieht, wie die MCP-Anbindung Experimenterstellung, Ergebnisabruf und Analyse in einem einzigen Dialog hält.
Ein paar Hinweise
- Die Oberfläche nutzen wir weiterhin. Die elluminate-Oberfläche ist stark für Exploration, das Durchsuchen vorhandener Ressourcen und die visuelle Prüfung komplexer Ergebnisse. Die MCP-Anbindung spielt ihre Stärken aus, wenn Sie wissen, wonach Sie suchen, und schnell iterieren wollen.
- Eindeutige Referenzen verwenden. Wer viele Experimente parallel fährt, sollte mit expliziten Experiment-IDs arbeiten statt mit „dem letzten Experiment” oder „der Baseline”. Das hält alles sauber.
Die unerwartete Erkenntnis
Zu Beginn dachten wir, die eigentliche Herausforderung sei Prompt Engineering: die richtigen Anweisungen für die Testgenerierung zu formulieren. Schnelles Iterieren hat etwas anderes zutage gefördert. Der echte Engpass war unser eigenes Verständnis davon, was einen Test wirksam macht. Jedes Experiment zwang uns, zu benennen, warum etwas funktionierte oder nicht – und genau dieses Benennen hat unser Denken schneller geschärft, als es jede Vorabplanung gekonnt hätte.
Fazit
Was wir daraus vor allem mitgenommen haben, sind mehr Iterationen. Wenn jeder Zyklus langsam ist, wird man konservativ: Man testet nur Ideen, von denen man überzeugt ist, bündelt Änderungen und schiebt Experimente auf. Ist Iteration schnell, kann man Intuitionen nachgehen und gründlicher erkunden.
Für dieses Projekt hat die MCP-Anbindung elluminate weniger wie ein separates Tool wirken lassen und mehr wie einen Teil unseres Entwicklungsflusses. Das Ergebnis war nicht nur eine bessere Erfolgsrate. Es waren Tests, die tatsächlich etwas Nützliches darüber ausgesagt haben, wie sich unsere Systeme verhalten.
Am Ende der Session hatten wir ein klares Bild davon, wo jedes Modell über sämtliche Evaluationsdimensionen stand – die Art von Zusammenfassung, die manuell Stunden gedauert hätte.
FAQ
Was ist MCP (Model Context Protocol)?
MCP ist ein Standard, über den KI-Assistenten direkt mit externen Tools und Diensten interagieren können. Statt Daten zwischen Anwendungen zu kopieren, kann ein MCP-kompatibler Assistent APIs aufrufen, Ergebnisse abholen und Aktionen in Ihrem Namen ausführen – alles innerhalb des Dialogs. Stellen Sie sich MCP als die Hände Ihres KI-Assistenten vor, mit denen er Ihre vorhandenen Tools bedient.
Wie richte ich den MCP-Server von elluminate ein?
Der MCP-Server von elluminate verbindet Ihren KI-Coding-Assistenten direkt mit der Evaluierungsplattform. Die Einrichtung dauert wenige Minuten: Sie konfigurieren die Verbindung in den MCP-Einstellungen Ihres Assistenten und authentifizieren sich mit Ihrem elluminate-Konto. Die Schritte finden Sie in unserem MCP-Integrationsleitfaden.
Welche Modelle kann ich mit elluminate evaluieren?
elluminate bringt eine große Auswahl integrierter Modelle mit, und Sie können zusätzlich eigene Endpunkte anbinden. So evaluieren Sie genau die KI-Systeme, die Sie in der Produktion betreiben – und keinen Stellvertreter.
Was kann der MCP-Server?
Der MCP-Server von elluminate bildet die Kernfunktionen der Plattform ab: Experimente anlegen und starten, Ergebnisse abrufen und vergleichen, Test-Collections verwalten, Evaluationskriterien durchsuchen und in einzelne Testfälle hineinzoomen.
Bereit, Ihre KI-Evaluation zu beschleunigen?
Der MCP-Server steht allen elluminate-Nutzern zur Verfügung. Den hier beschriebenen Workflow können Sie also direkt auf Ihre eigenen Evaluationsaufgaben anwenden. Wenn Sie Unterstützung beim Einstieg möchten oder besprechen wollen, wie das zu Ihren Prozessen passt, sprechen wir gerne mit Ihnen.





