Eine deutsche Krankenversicherung wollte ihre Website um eine KI-gestützte Suche erweitern. Nutzer sollten Fragen wie „Übernimmt mein Tarif die professionelle Zahnreinigung?” stellen und hilfreiche Antworten bekommen – statt einer Liste von Links. Die Herausforderung: Wie weist man nach, dass die KI korrekte Auskünfte zu Versicherungsleistungen gibt, bevor sie an Millionen von Nutzern ausgeliefert wird?
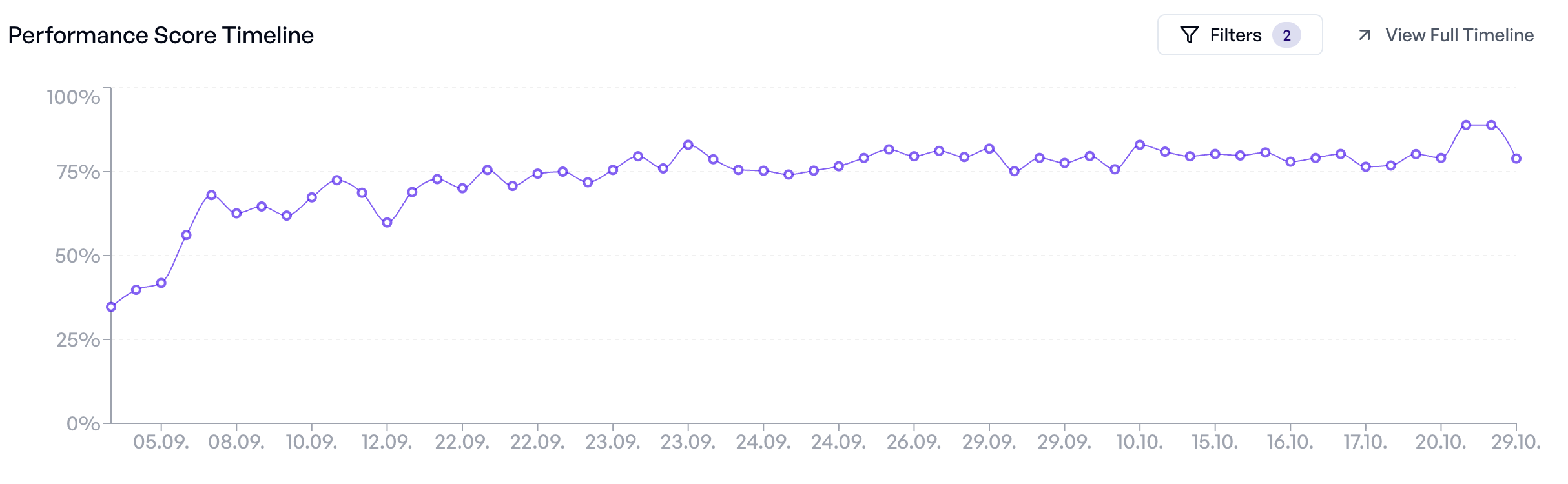
Gemeinsam mit dem Team haben wir ein Test-Set aus 50 Fällen aufgebaut – basierend auf den häufigsten Fragen, die Nutzer schon in die bestehende Suche eingaben. In sieben Wochen und 57 Experimenten haben wir das System von einer Erfolgsrate von 35 % auf über 80 % gebracht, obwohl wir parallel immer härtere Fälle ergänzt haben. Zum Launch konnten die Stakeholder exakt sehen, welche Fragen die KI sicher beantwortet und wo noch Lücken bestanden. Das Test-Set machte Entscheidungen erst möglich.
Dieser Beitrag zeigt, was wir dabei gelernt haben. Wir erklären, wie Sie ein Test-Set aufbauen, das Fehler vor den Nutzern aufdeckt, wie Sie verwertbare Labels von Fachexperten bekommen, ohne sie zu überlasten, und wie Sie Ihr Test-Set relevant halten, während sich Ihr Produkt weiterentwickelt.
Was ist ein Test-Set?
Ein Test-Set ist eine Sammlung von Eingaben, gegen die Sie Ihre KI laufen lassen, um deren Leistung zu messen. Jeder Testfall enthält typischerweise:
- Eingabevariablen: die Daten, die Sie an Ihren Prompt übergeben (eine Nutzerfrage, ein Dokument, eine Produktbeschreibung).
- Ground-Truth-Labels: was eine korrekte Antwort enthalten oder leisten muss. Das ist Ihr Bewertungsmaßstab.
- Metadaten: Tags wie Kategorie, Schwierigkeit oder Quelle, mit denen Sie Ergebnisse filtern und Muster erkennen.

Im Krankenversicherungs-Projekt sah ein Testfall so aus:
Anfrage: „Übernimmt meine Versicherung die professionelle Zahnreinigung?”
Erwarteter Inhalt: Ja, einmal jährlich kostenfrei in teilnehmenden Zahnarztpraxen des Netzwerks oder über das Bonusprogramm als Gesundheitszuschuss.
Erwartete Links: /benefits/dental-cleaning
Was hier bewusst fehlt: eine vollständige Musterantwort. Wir haben die Experten nicht gebeten, die perfekte Antwort zu formulieren. Wir haben sie gebeten, festzulegen, welche Fakten enthalten sein müssen und welche Links verlinkt werden sollen. Dieser Unterschied ist entscheidend – dazu später mehr.
Mit echten Nutzerdaten starten
Das wichtigste Prinzip: Ihre Testfälle müssen aus der echten Nutzung stammen. Synthetische Beispiele helfen, Lücken zu schließen, aber nichts ersetzt echte Fragen von echten Nutzern.
Für die KI-Suche haben wir die 50 häufigsten Anfragen aus den Logs der bestehenden Website-Suche gezogen. Keine hypothetischen Beispiele, sondern die Fragen, die Nutzer tatsächlich am häufigsten eingetippt haben. Das hat uns von Anfang an die Sicherheit gegeben, das Richtige zu testen.
Ihr Test-Set sollte abdecken:
- Häufige Fälle: die alltäglichen Fragen, die den Großteil des Traffics ausmachen. Fehler hier fallen Nutzern sofort auf.
- Varianten in der Formulierung: Nutzer fragen dasselbe auf viele Arten. „Wie lautet die Kundenservice-Nummer?”, „wie erreiche ich den Support”, „Telefonnummer bitte”, „RUFT IHR MICH AN???” – Ihre KI muss damit umgehen können.
- Seltene, aber gültige Fälle: ungewöhnliche Szenarien, die trotzdem funktionieren müssen. Bei einer Krankenversicherung können das Fragen zu speziellen Tarifdetails oder Edge Cases im Leistungsumfang sein.
Wenn Ihnen noch keine Produktivdaten vorliegen, starten Sie mit dem, was da ist: Support-Tickets, Transkripte von Vertriebsgesprächen oder Fragen aus Nutzerinterviews. Entscheidend ist, Ihr Test-Set in der Realität zu verankern, nicht in Annahmen.
Gezielt Fehlermuster angehen
Allgemeine Test-Sets zeigen, dass etwas kaputt ist. Gezielte Test-Sets zeigen, was genau.
Im Krankenversicherungs-Projekt stießen wir auf ein hartnäckiges Muster: Die KI beantwortete Fragen nach Telefonnummern korrekt – aber die Fachexperten wollten genau das nicht. Nutzer sollten stattdessen auf das Kontaktformular gelenkt werden, weil Formularanfragen schneller bearbeitet werden als Anrufe.
Das Modell ignorierte diese Anweisung beharrlich. Selbst nach wiederholten Anpassungen des Prompts lieferte es weiter die Telefonnummer aus. Um das zu lösen, haben wir eine kleine, fokussierte Sammlung aufgebaut: 8 verschiedene Formulierungen, mit denen Nutzer nach Telefonnummern fragen. „Wie ist eure Telefonnummer?”, „Wie kann ich euch anrufen?”, „Ich muss mit jemandem sprechen”, „Kundenservice-Hotline” und so weiter.
Dieses Mini-Test-Set erlaubte uns, genau dieses Verhalten schnell zu iterieren. Experimente liefen in Sekunden statt Minuten. Wir konnten verschiedene Prompt-Formulierungen und Few-Shot-Beispiele durchprobieren, bis das Modell zuverlässig die gewünschte Vorgabe einhielt. Sobald es funktionierte, haben wir zwei repräsentative Fälle in die Hauptsammlung übernommen – als Absicherung gegen Regressionen.
Das Muster: Wenn Sie eine Fehlerkategorie identifizieren, legen Sie eine fokussierte Sammlung mit 5 bis 10 gezielten Fällen an. Nutzen Sie sie für schnelle Iterationen. Sobald das Problem gelöst ist, übernehmen Sie einige Fälle in Ihre Hauptsammlung.
Zu den Edge Cases, auf die Sie achten sollten, gehören fehlerhafte Eingaben (Tippfehler, gemischte Sprachen, fehlende Satzzeichen), adversariale Eingaben (Prompt-Injection-Versuche, unsinnige Anfragen), Grenzfälle (sehr lange oder sehr kurze Eingaben, leere Felder) und mehrdeutige Fälle, bei denen die richtige Antwort nicht offensichtlich ist.
Labels, die Ihre Experten nicht ausbrennen
An diesem Punkt laufen die meisten Teams falsch: Sie bitten Fachexperten, für jeden Testfall eine vollständige Musterantwort zu verfassen. Das ist langsam, mühsam und oft kontraproduktiv. Experten brennen aus. Antworten werden inkonsistent. Und Exact-Match-Evaluation ist ohnehin fragil – es gibt viele Wege, dieselbe Sache korrekt zu sagen.
Bitten Sie Experten stattdessen, die Mindestanforderungen festzulegen: welche Fakten enthalten sein müssen und welche Links verlinkt werden sollen. Das ist schneller geschrieben, leichter zu prüfen und robuster in der Evaluation.
Im Krankenversicherungs-Projekt:
- Wir haben erste Label-Entwürfe mit einem starken Modell erzeugt (für den Produktivbetrieb zu teuer, aber als Startpunkt ideal).
- Fachexperten haben diese Entwürfe geprüft, korrigiert und mit ihrem Fachwissen angereichert – insbesondere mit dem, was zwingend erwähnt werden muss.
- 5 Experten haben je etwa 1 Stunde für 10 Fälle aufgewendet – rund 5 Stunden insgesamt für das initiale 50-Fall-Set.
Die Experten waren erleichtert. Sie mussten keine perfekten Fließtexte formulieren. Es reichte zu sagen: „Bei dieser Frage muss die Antwort X und Y erwähnen und auf Seite Z verlinken.” Das konnten sie schnell und sicher liefern.
Beispiel – einfache, aber klare Vorgabe:
Anfrage: „Wie lautet die Telefonnummer des Kundenservice?”
Erwarteter Inhalt: Sollte auf das Kontaktformular als primäre Option verweisen.
Erwartete Links: /contact/form
Dieses Format macht auch die Evaluationskriterien geradlinig. Sie können Kriterien formulieren wie: „Enthält die Antwort die erwarteten Fakten?” und „Verlinkt die Antwort auf die erwarteten Seiten?” Binär, eindeutig und über Ihr gesamtes Test-Set hinweg wiederverwendbar.
Ein Beispielkriterium, das Ground Truth referenziert:
Deckt die Antwort die erforderlichen Informationen ab? Erforderlich:
{{expected_content}}Behandeln Sie Ihr Test-Set als lebendes Dokument
Ein Test-Set baut man nicht einmal auf und vergisst es dann. Es entwickelt sich mit Ihrem Produkt.
Im gesamten Krankenversicherungs-Projekt haben wir die Sammlung lebendig gehalten. Fehler beim Labeling haben wir sofort korrigiert. Wenn sich die zugrunde liegenden Daten änderten – eine Leistung angepasst, eine Seite verschoben –, haben wir den erwarteten Inhalt nachgezogen. Wenn Nutzertests Lücken offenbarten, Fragen, mit denen wir nicht gerechnet hatten, haben wir sie ergänzt.
Wir starteten mit 50 Fällen und kamen zum Launch bei 80 an. Das Test-Set ist nicht durch willkürliche Erweiterung gewachsen, sondern aus konkretem Bedarf.
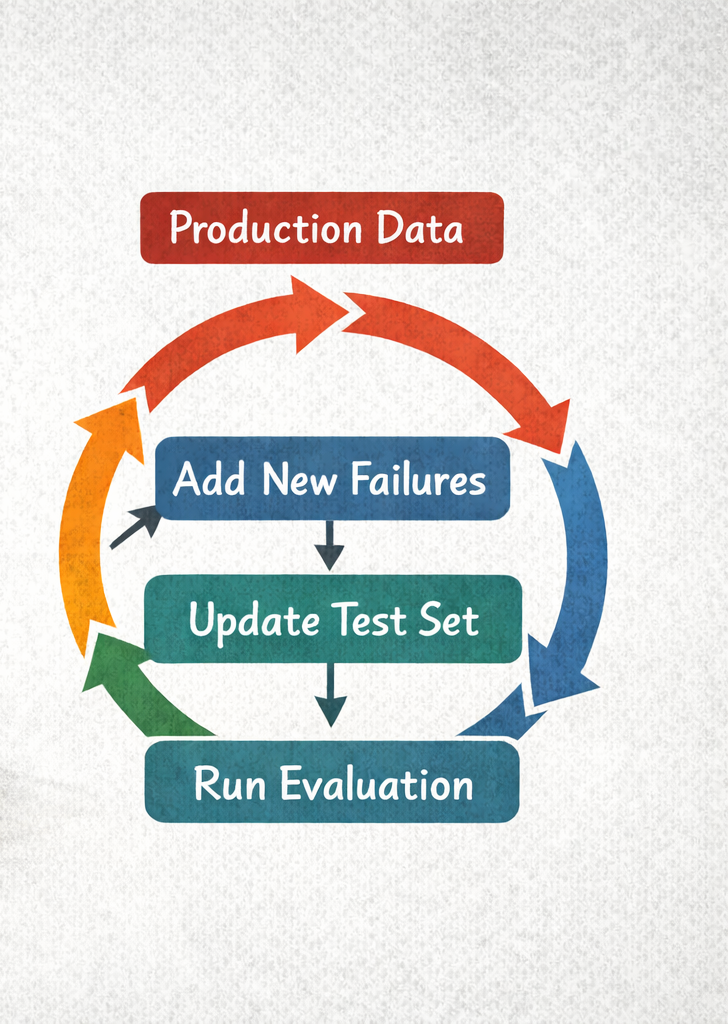
Wann Sie Ihr Test-Set aktualisieren sollten:
- Nach jedem Incident im Produktivbetrieb: Wenn Nutzer auf einen Fehler stoßen, wandert dieser Fall ins Test-Set. Denselben Bug sollten Sie nie zweimal sehen.
- Bei größeren Prompt-Änderungen: Neues Verhalten braucht neue Tests.
- Wenn sich zugrunde liegende Daten ändern: Aktualisiert sich Ihre Wissensbasis, können Ihre Labels veraltet sein.
- Wenn Sie Muster in Fehlern erkennen: Häufungen ähnlicher Fehler bedeuten, dass Sie in diesem Bereich mehr Abdeckung brauchen.
Nach dem Go-live haben wir weiter Fälle aus der echten Nutzung ergänzt. Spannende Fehlschläge wurden zu Testfällen. Das Test-Set wurde mit der Zeit immer repräsentativer.
Ein Workflow für die Praxis
So sah der Prozess aus, der im Krankenversicherungs-Projekt funktioniert hat – und den wir quer durch viele Teams bewährt sehen:
- Echte Anfragen ziehen: Starten Sie mit 30 bis 50 Beispielen aus Produktiv-Logs, Support-Tickets oder Nutzerrecherche. Das ist Ihr Fundament.
- Label-Entwürfe erzeugen: Lassen Sie ein starkes Modell erste Ground-Truth-Antworten generieren. Das ist kein Endergebnis, sondern ein Startpunkt für die Experten.
- Expertenreview: Lassen Sie Fachexperten je 1 bis 2 Stunden investieren, um die Labels zu korrigieren und anzureichern. Fragen Sie nach Fakten und Links, nicht nach vollständigen Antworten.
- Erstes Experiment fahren: Verschaffen Sie sich einen Überblick. Suchen Sie nach Mustern in den Fehlern. Versagen bestimmte Kategorien? Bestimmte Formulierungen?
- Gezielte Mini-Sets aufbauen: Für hartnäckige Fehlermuster legen Sie kleine, fokussierte Sammlungen mit 5 bis 10 Fällen an. Schnell iterieren. Die Gewinner wandern ins Hauptset.
- Lebendig halten: Labels anpassen, wenn sich Daten ändern. Fälle ergänzen, wenn Lücken auftauchen. Fälle entfernen, die nicht mehr relevant sind.

Typische Fehler
- Nur Happy Paths testen: Wenn jeder Testfall eine wohlgeformte, häufige Frage ist, testen Sie nicht – Sie bestätigen Ihre Hoffnungen.
- Zu wenige Fälle: Mit 10 bis 20 Fällen haben Sie keine statistische Aussagekraft. Starten Sie mit mindestens 50.
- Zu viele Fälle: Ab 150 bis 200 wird die Pflege schwierig. Wenn Sie dort sind, teilen Sie besser in fokussierte Sammlungen auf.
- Experten vollständige Antworten schreiben lassen: Das brennt sie aus und produziert inkonsistente Labels. Fragen Sie stattdessen nach Fakten und Links.
- Statische Test-Sets: Ein Test-Set, das Sie vor sechs Monaten aufgebaut und nie angefasst haben, belügt Sie. Halten Sie es aktuell.
- Produktivdaten ignorieren: Synthetische Beispiele sind eine sinnvolle Ergänzung, aber echte Nutzeranfragen sind unersetzbar.
Der Nutzen
In sieben Wochen hat das Team der Krankenversicherung 57 Experimente gefahren – 20 Prompt-Versionen, 10 Systemänderungen, mehrere Modellvergleiche. Jedes Experiment lief in Minuten und lieferte klare Ergebnisse. Die Erfolgsrate stieg von 35 % auf über 80 %, obwohl wir parallel härtere Fälle ergänzt haben.
Noch wichtiger: Das Test-Set machte Entscheidungen erst möglich. Wenn Stakeholder fragten „Ist das bereit für den Launch?”, konnten wir exakt zeigen, welche Fragen funktionierten und welche nicht. Wir konnten Risiken quantifizieren. Wir konnten Fixes priorisieren. Das Test-Set hat „Ich glaube, das läuft” in „Das wissen wir” verwandelt.
Nach dem Launch zahlte sich das Test-Set weiter aus. Fehler aus dem Produktivbetrieb wurden zu Testfällen. Das System wurde immer besser. Die anfänglichen 5 Stunden Expertenzeit sind inzwischen über Dutzende Experimente wiederverwendet worden – und werden es, solange das Produkt existiert.
Genau das zeichnet ein gutes Test-Set aus: Es verzinst sich. Einmal richtig aufgebaut und konsequent aktuell gehalten, wird es zum Fundament jeder weiteren Verbesserung.
Unterstützung beim Aufbau Ihres Test-Sets?
Wir arbeiten direkt mit Teams zusammen, um Test-Sets und Evaluationsworkflows für ihre konkreten Anwendungsfälle zu entwerfen. Wenn Sie KI bauen und zuverlässig liefern wollen, sprechen Sie uns an.





