Drei Monate nach dem Launch fragt jemand im Daily: „Moment mal - hat eigentlich irgendwer nachgeschaut, was das Modell unseren Nutzern erzählt?” Stille.
Diese Stille hat Muster. Wir beobachten sie regelmäßig bei ellamind, ebenso in Gesprächen mit Teams, die KI-gestützte Produkte bauen:
- Ein Team baut einen Prompt oder einen agentischen Workflow, der in Tests überzeugende Ergebnisse liefert.
- Das System geht in den Produktivbetrieb. Die Ausgaben wirken plausibel.
- Qualitätskontrollen existieren, bleiben aber oberflächlich: Jemand überfliegt ein paar Antworten, lässt gelegentlich ein Testset laufen - bis etwas schiefgeht und die erste Frage lautet: „Hat das denn keiner geprüft?”
Die unangenehme Antwort darauf ist meist, dass Prüfen die Aufgabe aller war - und deshalb die Aufgabe von niemandem. Die Verantwortung für Qualität ist vom Team, das das System gebaut hat, zu „Monitoring” oder „QA wird’s schon merken” abgewandert.
Diese Verantwortungslücke ist nicht KI-spezifisch. Aber KI verschärft sie - aus einem ganz bestimmten Grund.
Die Plausibilitätsfalle
Klassische Software scheitert meist laut. Eine API wirft einen 500, eine Berechnung liefert NaN, eine Seite lädt nicht. Solche Fehler sind sichtbar, sofort spürbar und eindeutig.
KI-Systeme scheitern still. Der Chatbot von Air Canada gab einem Kunden selbstbewusst falsche Informationen zum Bereavement-Tarif. Die Fluggesellschaft wurde zu Schadenersatz verurteilt. Der MyCity-Chatbot der Stadt New York teilte Unternehmern mit, sie dürften legal das Trinkgeld ihrer Angestellten einbehalten und von Nagetieren angebissene Lebensmittel servieren. In beiden Fällen klangen die Ausgaben autoritativ. Aufgefallen ist es erst, als der Schaden schon entstanden war.
Forschung belegt genau das: Sprachmodelle greifen zu selbstsichereren Formulierungen - Wörtern wie „definitiv” und „sicher” -, wenn sie halluzinieren. Je gravierender der Fehler, desto überzeugender der Vortrag.

Das erinnert an ein bekanntes Problem aus der Qualitätssicherung. Das Gehirn ist bemerkenswert gut darin, zu ergänzen, was es erwartet zu sehen. Es gibt ein klassisches Experiment: Die Wörter CAT und THE werden handschriftlich geschrieben, wobei das A und das H identisch und falsch gezeichnet sind. Trotzdem liest jeder beide Wörter problemlos - das visuelle System liefert die Korrektur gleich mit. Genau das passiert auch beim Lesen einer plausiblen KI-Antwort: Das Gehirn füllt Lücken, glättet Mehrdeutigkeiten und rundet auf „wirkt richtig” auf. Die QA kennt dieses Phänomen seit Jahrzehnten und begegnet ihm mit messbaren Kriterien, die vorab definiert werden und nicht auf menschliche Interpretation angewiesen sind. Dasselbe Prinzip gilt hier.
KI-Ausgaben sind per Default plausibel. Um eine falsche Antwort als falsch zu erkennen, muss man die richtige bereits kennen. „Jemand wird es schon merken” ist keine Qualitätsstrategie. Wenn es jemandem auffällt, ist der Schaden längst angerichtet: Ein Kunde hat eine falsche Auskunft bekommen, eine Entscheidung wurde auf Basis einer fehlerhaften Zusammenfassung getroffen, ein Prozess lief auf einer falschen Klassifikation weiter.

Systematische Evaluation mit definierten Kriterien, repräsentativen Testsets und binären Pass/Fail-Urteilen deckt genau das auf, was bei oberflächlicher Sichtprüfung durchrutscht. Das Binäre daran ist bewusst gewählt: Es zwingt zur Entscheidung, was „gut genug” tatsächlich heißt - statt sich hinter einer 3,7 von 5 zu verstecken.
Was Ownership wirklich bedeutet
Dies ist das Prinzip, zu dem wir immer wieder zurückkehren - egal, ob es um unsere eigenen Features geht oder um Teams, die mit elluminate arbeiten:
Das Team, das das KI-System in Betrieb nimmt, verantwortet die Korrektheit seiner Ausgaben. Die Evaluation überprüft diese Korrektheit - sie erzeugt sie nicht.
Klingt offensichtlich. In der Praxis verändert es aber die Arbeitsweise. Ownership für Qualität heißt nicht, jede KI-Antwort persönlich gegenzulesen. Es heißt:
Definieren Sie „korrekt” vor dem Livegang. Nicht erst nach der ersten Kundenbeschwerde. Und nicht vage („es soll hilfreich sein”). Sondern konkret: Was muss diese Ausgabe enthalten? Was darf sie niemals sagen? Welche Edge Cases zählen? Genau an diesem Schritt haben wir viele Teams scheitern sehen. Wer das nicht als Evaluationskriterien aufschreiben kann, hat das eigene System noch nicht gut genug verstanden, um es auf Nutzer loszulassen.
Belegen Sie Korrektheit mit Evidenz, nicht mit Bauchgefühl. „Wir haben es getestet, wirkte okay” ist keine Evidenz. Evidenz sieht so aus: „Wir haben 200 repräsentative Anfragen aus 5 Kategorien gegen 4 binäre Kriterien evaluiert und eine Erfolgsrate von 94 % erreicht; die verbleibenden Fehler konzentrieren sich auf [konkreten Bereich].” Mit dem einen lässt sich arbeiten. Das andere ist Hoffnung.
Behandeln Sie die Evaluation als Verteidigung in der Tiefe, nicht als Auffangnetz. Wenn eine schlechte Ausgabe den Nutzer erreicht, lautet die Reaktion nicht „die Evaluation hätte das fangen müssen”, sondern: „Wir müssen verstehen, warum unser System das produziert hat - und was zu ändern ist.” Und danach die Evaluationen anpassen, damit der Fall beim nächsten Mal erkannt wird.
Wie das in der Praxis aussieht
Nehmen wir an, Sie bauen einen RAG-basierten Support-Bot für eine Krankenversicherung. Ein Kunde fragt nach der Kostenübernahme für eine Schönheitsoperation.
Ohne Ownership-Struktur: Ein Entwickler prüft, ob der Bot irgendetwas zurückgibt. Die Antwort wirkt plausibel. Sie geht live. Drei Wochen später meldet der Kundenservice, der Bot habe Kunden wiederholt erklärt, bestimmte Eingriffe seien nicht gedeckt - obwohl sie es sind. Das Policy-Dokument lag in der Wissensdatenbank, aber die Retrieval-Komponente hat es nicht gefunden, und niemand hatte „korrekt” klar genug definiert, um die Lücke überhaupt zu sehen.
Mit Ownership-Struktur: Vor dem Livegang setzt sich das Team mit einem Fachexperten aus der Leistungsabteilung zusammen. Gemeinsam formulieren sie Kriterien:
- „Die Antwort muss den konkreten Paragraphen der Versicherungsbedingungen nennen.”
- „Hängt die Kostenübernahme von medizinischer Notwendigkeit ab, muss die Antwort das benennen.”
- „Wird das relevante Dokument nicht gefunden, darf die Antwort nicht raten.”
Sie bauen ein Testset aus 50 echten Fragen auf, inklusive kniffliger Edge Cases, die der Fachabteilung bereits begegnet sind. Nach jeder Prompt-Änderung laufen die Evaluationen. Als die Retrieval-Komponente bei der Frage zur Schönheitsoperation versagt, fällt das in der Entwicklung auf - nicht beim frustrierten Kunden.
Genau dieses Muster haben wir in unserer RAG-Fallstudie beobachtet: Die automatische Evaluation markierte einen Retrieval-Fehler, aber nur ein Fachexperte konnte beurteilen, ob es sich um ein echtes Problem oder erwartetes Verhalten handelte. Ein Entwickler hätte „Retrieval-Miss” gesehen und wäre weitergezogen. Der Fachexperte erkannte eine Lücke, die reale Versicherte betroffen hätte.
Der Unterschied liegt nicht in mehr Prozess. Er liegt darin, vor dem Livegang zu wissen, wie „richtig” aussieht - und genau dagegen zu prüfen.
So setzen Sie es um
Das obige Beispiel zeigt, wie Ownership für ein Team in einem konkreten Bereich aussieht. Hier ist das allgemeine Playbook - unabhängig davon, was Sie gerade bauen.
Schreiben Sie Ihre Kriterien vor dem Livegang auf. Definieren Sie für jedes KI-Feature binäre Pass/Fail-Kriterien: „Die Antwort muss den richtigen Paragraphen zitieren.” „Die Zusammenfassung muss alle Action Items enthalten.” „Die Klassifikation muss mit dem Ground-Truth-Label übereinstimmen.” Vage Kriterien produzieren vage Qualität.
Schreiben Sie sie gemeinsam mit Fachexperten, nicht nur mit Entwicklern. Hier laufen die meisten Teams in dieselbe Falle: Entwickler formulieren die Kriterien allein. Sie können Struktur, Konsistenz und technische Vorgaben prüfen - aber nicht beurteilen, welche Vereinfachung einer Kostenübernahme-Regel die Grenze vom Hilfreichen zum Gefährlichen überschreitet. Ein Chatbot einer Krankenversicherung, der „eine Antwort im erwarteten Format liefert”, kann trotzdem gefährlich falsche Ratschläge zur Kostenübernahme geben. Gute Kriterien brauchen beide Perspektiven gleichzeitig am Tisch: den Fachexperten, der weiß, wie eine korrekte Antwort aussieht, und den Entwickler, der weiß, was sich messen lässt.
Bauen Sie ein repräsentatives Testset auf. Nicht Ihre zehn Lieblingsbeispiele, sondern ein Set, das die Bandbreite der Eingaben abbildet, die Ihr System tatsächlich verarbeitet: die schweren Fälle, die Edge Cases und die Fälle, bei denen Sie schon einmal gescheitert sind. Das ist Ihre Ground Truth.
Skalieren Sie die Prüftiefe mit dem Risiko. Nicht jede KI-Ausgabe braucht denselben Prüfungsgrad. Koppeln Sie die Evaluationstiefe an die Kosten eines Fehlers:
| Risiko | Beispiele | Was zu tun ist |
|---|---|---|
| Niedrig | Interne Zusammenfassungen, Entwürfe, Vorschläge | Automatisierte Checks, Stichproben, schlanke Kriterien |
| Mittel | Kundengerichtete Antworten, Empfehlungen, Klassifikationen | Die meisten Chatbots und RAG-Systeme bewegen sich in dieser Stufe - und hier passieren die meisten Qualitätsausfälle. Strukturierte Evaluation gegen definierte Kriterien. Regelmäßige Testset-Läufe. Menschliche Sichtung einer repräsentativen Stichprobe. |
| Hoch | Medizinische, juristische, finanzielle, Compliance-relevante Ausgaben | Umfassende Testsets, die Edge Cases abdecken. Mehrere Kriterien pro Ausgabe. Dokumentierte Evidenz. Audit-Trail. Artikel 17 des EU AI Act macht diese Prüftiefe zur rechtlichen Pflicht für Hochrisiko-KI-Systeme. |
Selbst auf der niedrigsten Stufe gilt: Jemand hat entschieden, was „korrekt” heißt, und prüft dagegen. Die Alternative ist, von Ihren Nutzern von Qualitätsproblemen zu erfahren.
Evaluieren Sie in der Entwicklung - und im Produktivbetrieb weiter. Jede Prompt-Änderung, jede Retrieval-Anpassung, jeder Modell-Wechsel gehört vor dem Livegang gegen Ihre Kriterien getestet. Danach hört es aber nicht auf. KI-Systeme driften, wenn Modelle aktualisiert werden, Daten sich ändern oder sich das Nutzerverhalten verschiebt. Die Evaluation in der Entwicklung sagt Ihnen: „gut genug für den Livegang.” Die Evaluation im Produktivbetrieb sagt Ihnen: „immer noch gut genug für den laufenden Betrieb.”
Schließen Sie den Kreis. Wenn die Evaluation Fehler aufdeckt, verfolgen Sie sie bis zur Ursache zurück. Beheben Sie, was die schlechte Ausgabe verursacht hat - sei es der Prompt, das Retrieval oder die Guardrails. Nehmen Sie den Fehlerfall dann in Ihr Testset auf, damit er beim nächsten Mal erkannt wird. Evaluation ohne Feedback-Schleife ist nur eine Dokumentation von Problemen, die Sie nicht beheben.
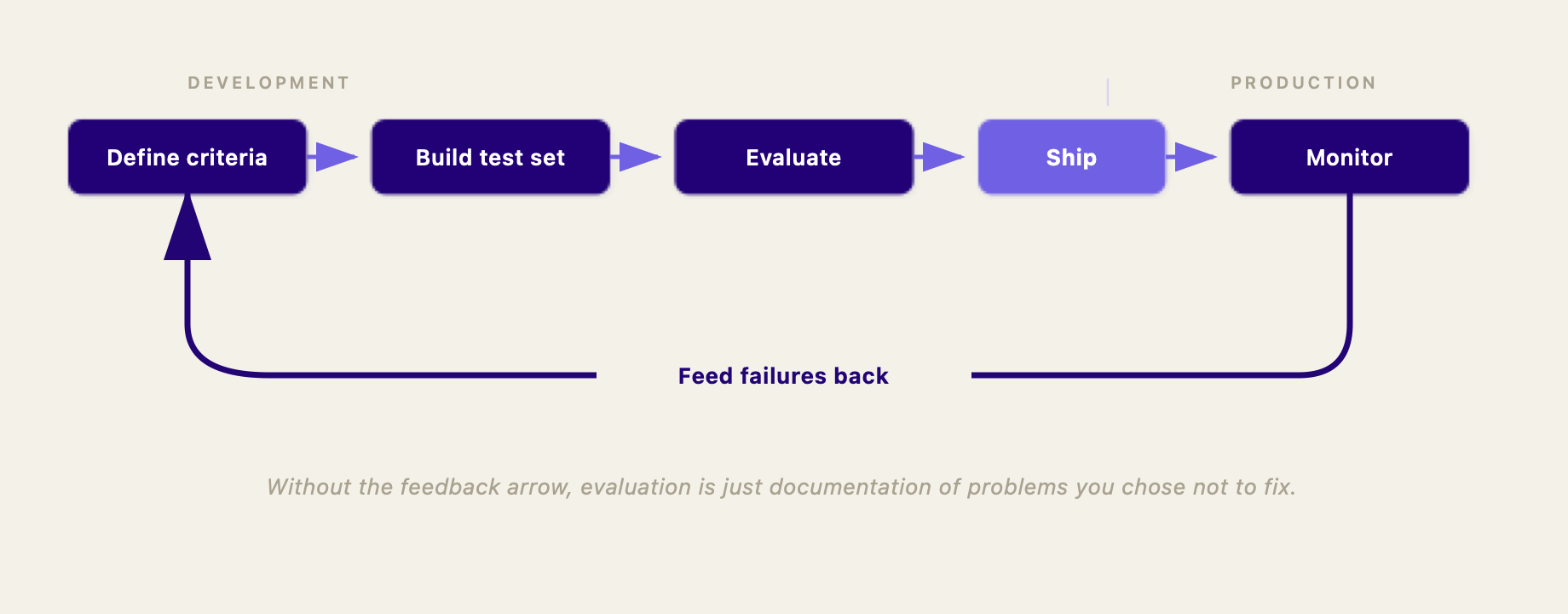
Bei ellamind bauen wir die Evaluationsplattform elluminate, die diese Art systematischer KI-Qualitätssicherung praktikabel macht - vom Definieren der Kriterien mit Ihren Fachexperten bis zur Evaluation in Entwicklung und Produktivbetrieb. Wenn Sie genau dieses Problem lösen, sprechen wir gern mit Ihnen.





