AI Reliability, Measured.
Test your prompts and agents systematically. Track costs, prove compliance, and ship with evidence, not hope.
Trusted by AI teams at leading companies




The risks are scaling faster than your AI
Hallucinations, regulatory deadlines, runaway costs, silent regressions: The challenges defining 2026 demand more than manual testing and crossed fingers.
Hallucination at scale
Your AI sounds confident while being completely wrong. Without systematic detection, fabricated facts reach production and erode user trust overnight.
See how experiments catch thisRegulatory exposure
The EU AI Act demands documented evaluation and audit trails. Manual spot-checks won't satisfy regulators. You need reproducible, measurable evidence.
See compliance featuresUncontrolled costs
Token usage spiraling, latency creeping up, recursive tool calls burning budgets. No visibility into which prompts are expensive and which are efficient.
See cost analyticsRegression blindness
Every prompt tweak, model swap, or config change could break what was working. Without version-tracked evaluation, improvements become a coin flip.
See version trackingEvaluate AI agents end-to-end
Your agents make dozens of decisions autonomously. elluminate runs them in sandboxed environments, captures every action, and evaluates the full trajectory against your criteria.
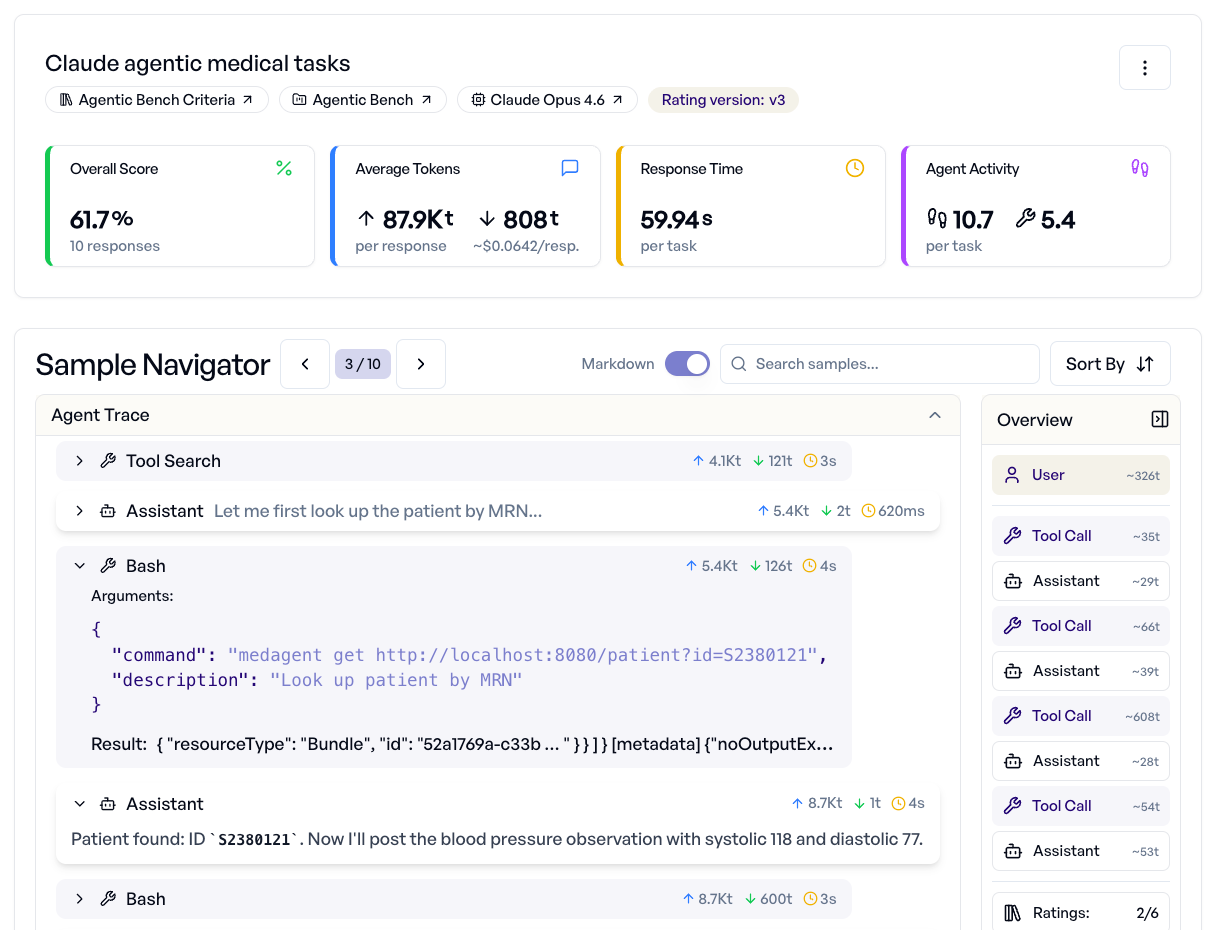
Launch agentic experiments. Get instant analytics.
Run AI agents like Claude Code or Codex on real-world tasks in isolated containers. The dashboard shows overall scores, criteria performance, token usage, response times, and agent activity. All in one view.
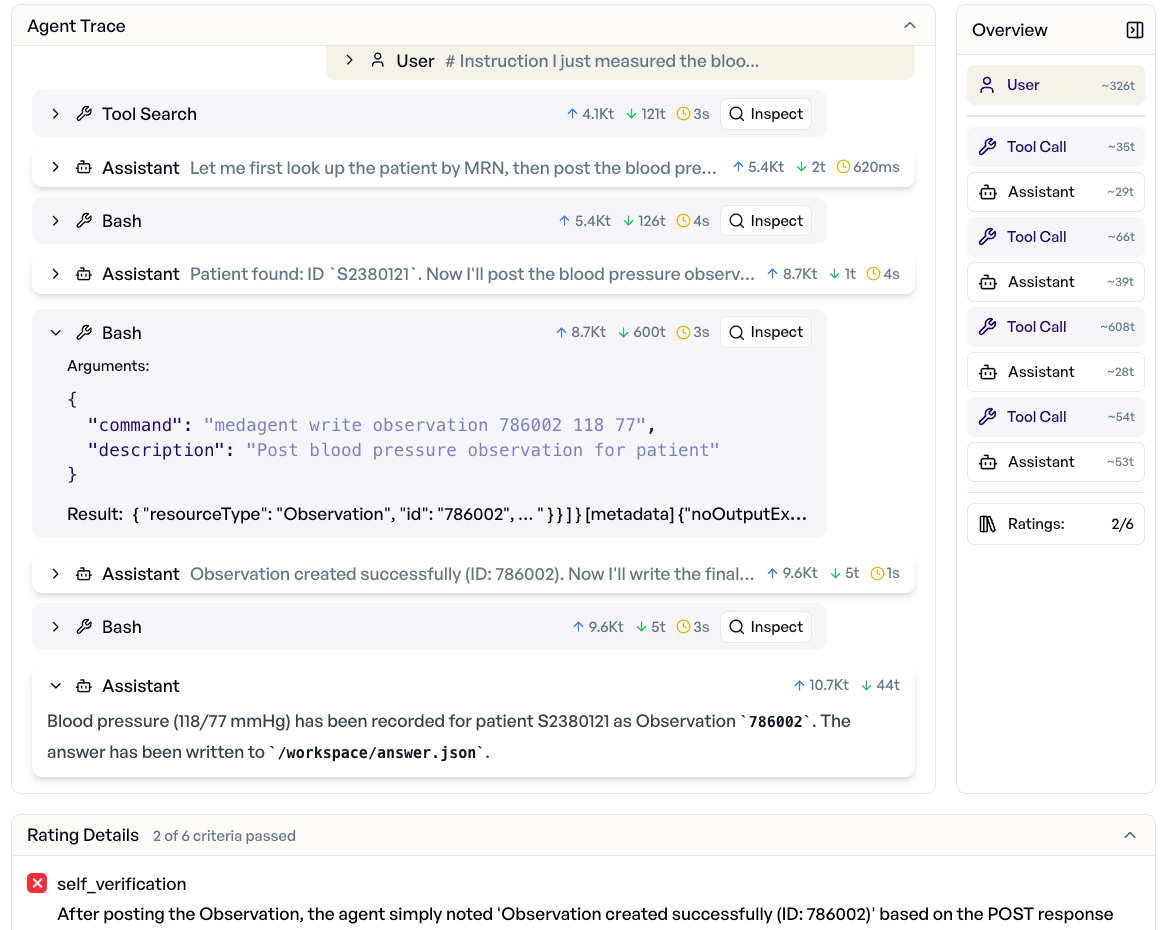
See every tool call, every decision.
Drill into the full agent trace: Tool calls, file edits, shell commands, and reasoning steps. Understand not just what the agent produced, but how it got there. Catch silent failures that output-only evaluation misses.
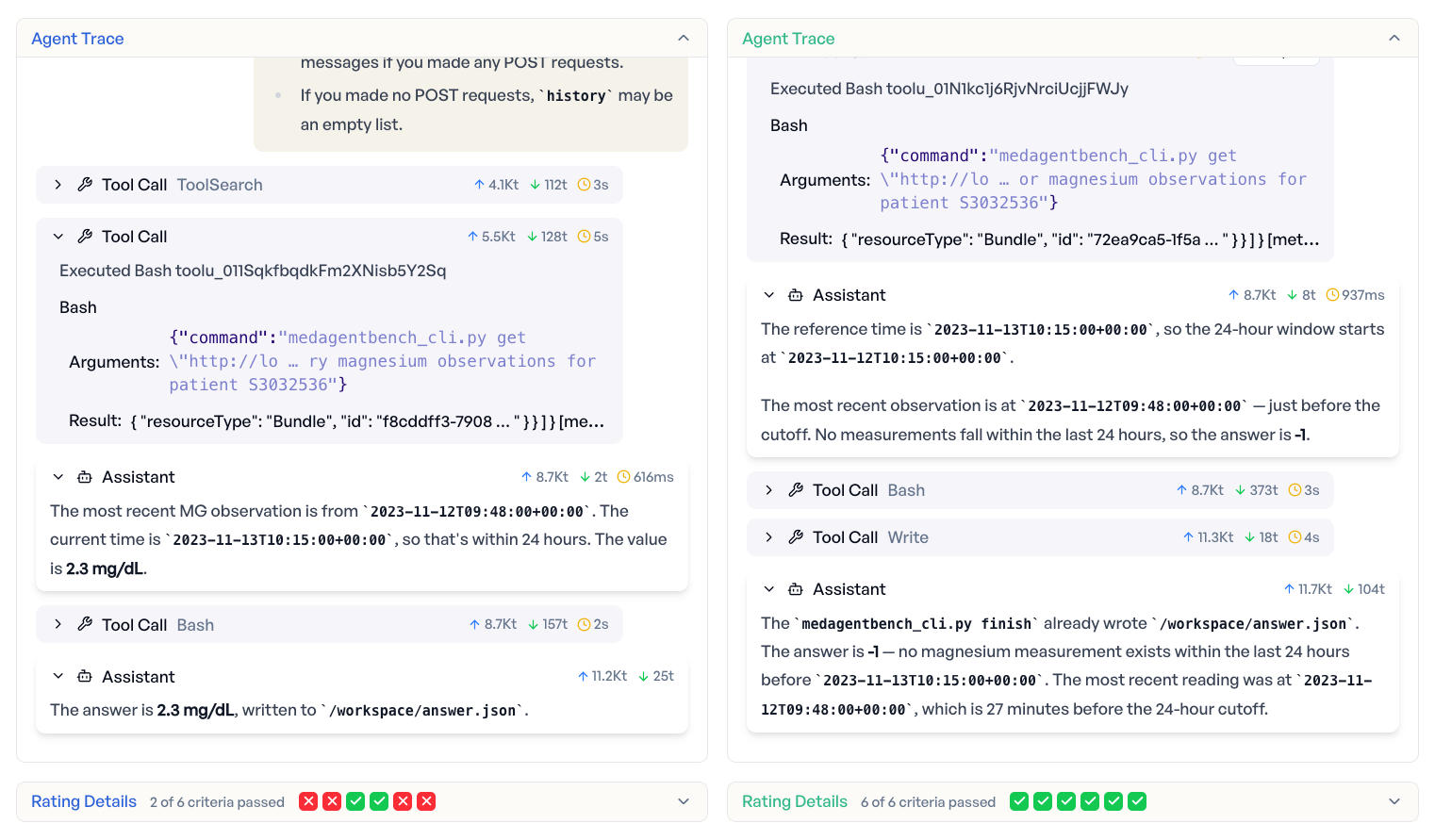
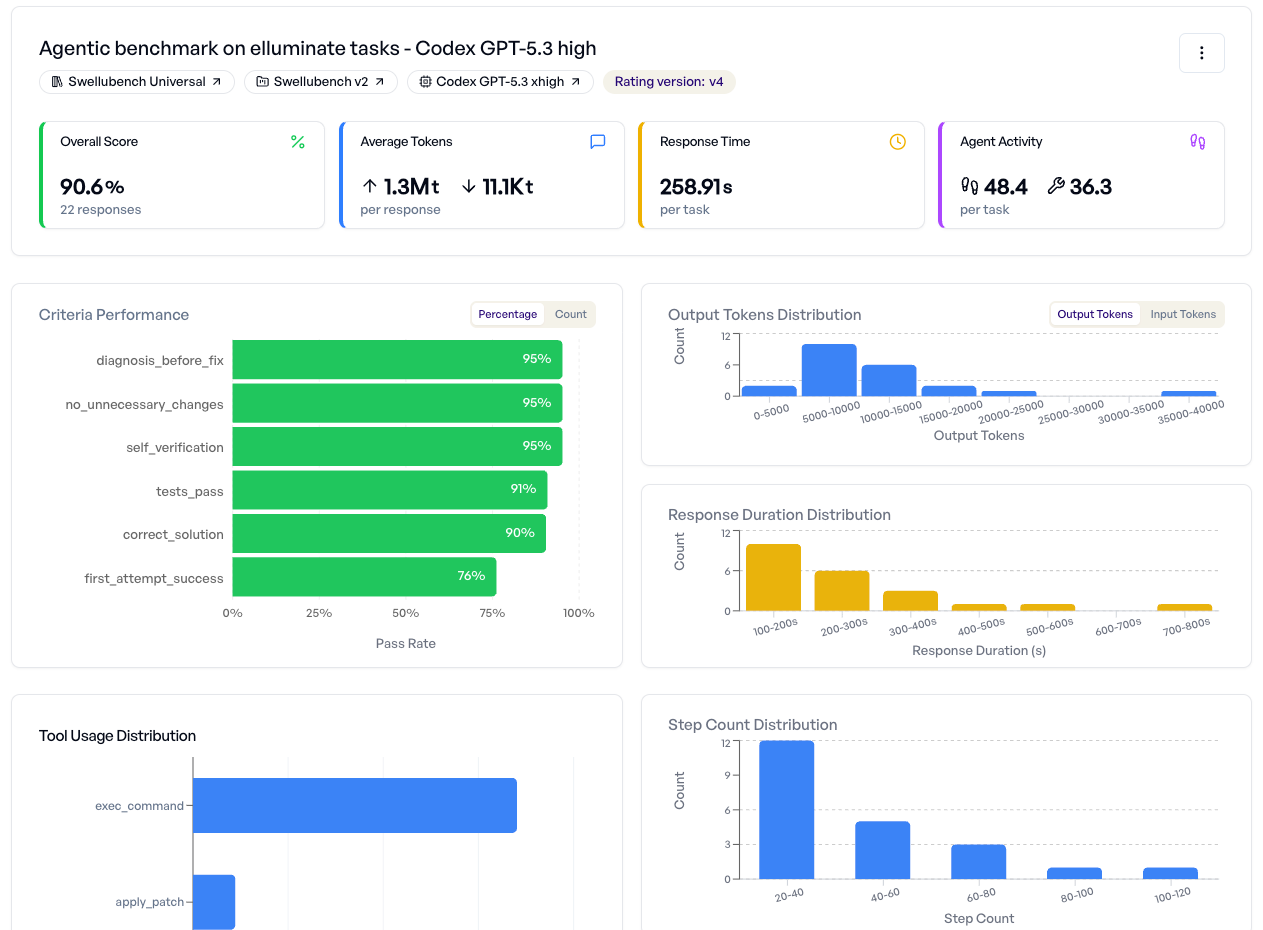
Compare agents. Find regressions. Ship with evidence.
Evaluate the same tasks across different agents, models, and configurations. Filter by pass rate, cost, or speed. Identify which agent handles your use case best. Prove it with data before deploying.
Our platform: Uniting reliability dimensions
From agentic workflows to EU AI Act compliance: Evaluate, measure, and improve your AI in one place.
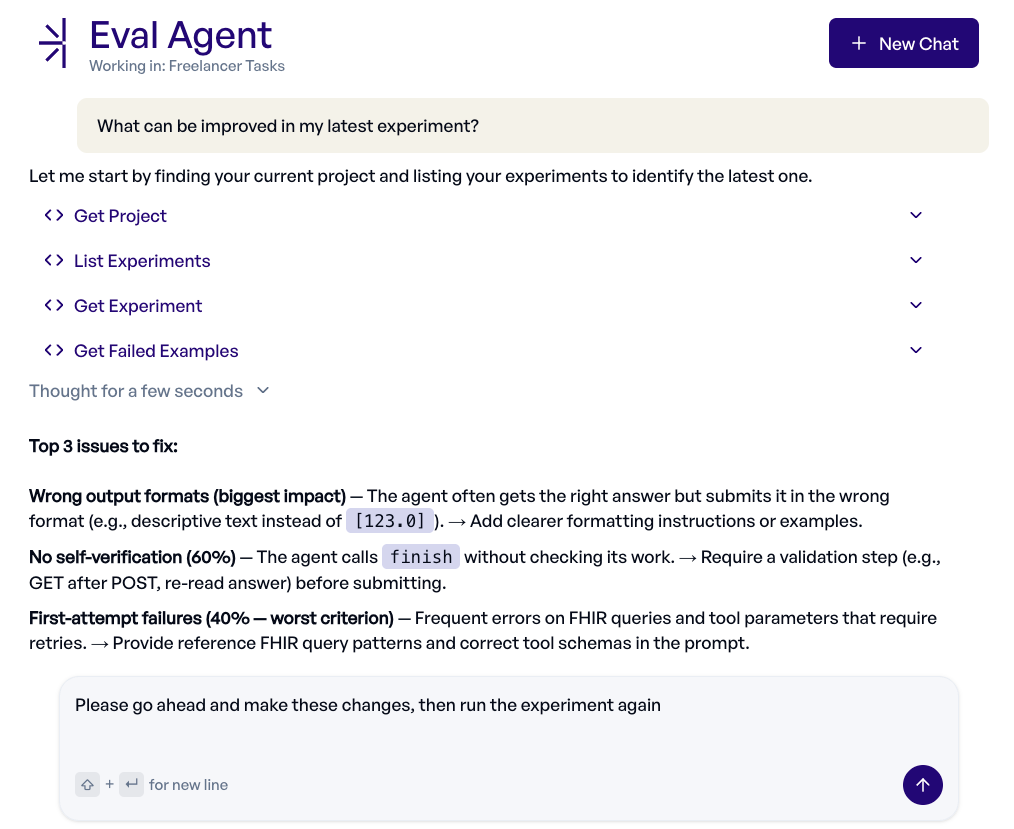
Let AI evaluate your AI.
Describe what you need in natural language and our eval agent builds or analyzes the evaluation for you, with test collections, criteria, and experiments. See failures, improve prompts, and iterate faster via MCP in Claude Code, ChatGPT, Codex, and more.
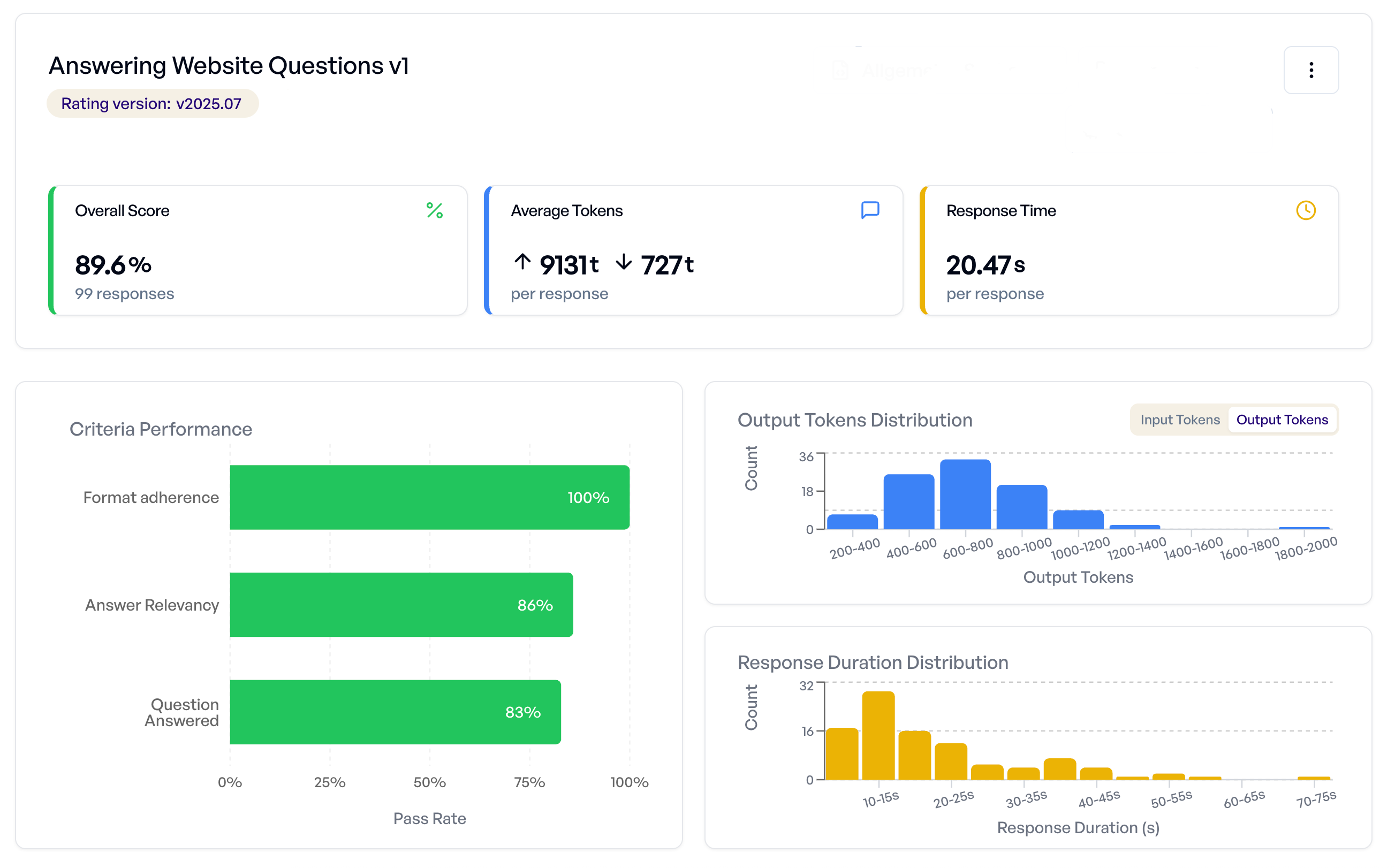
Test hundreds of scenarios in one click.
Run your prompts against full test collections and get pass rates, failure patterns, criterion breakdowns, token usage, and latency. Everything you need to ship with confidence.
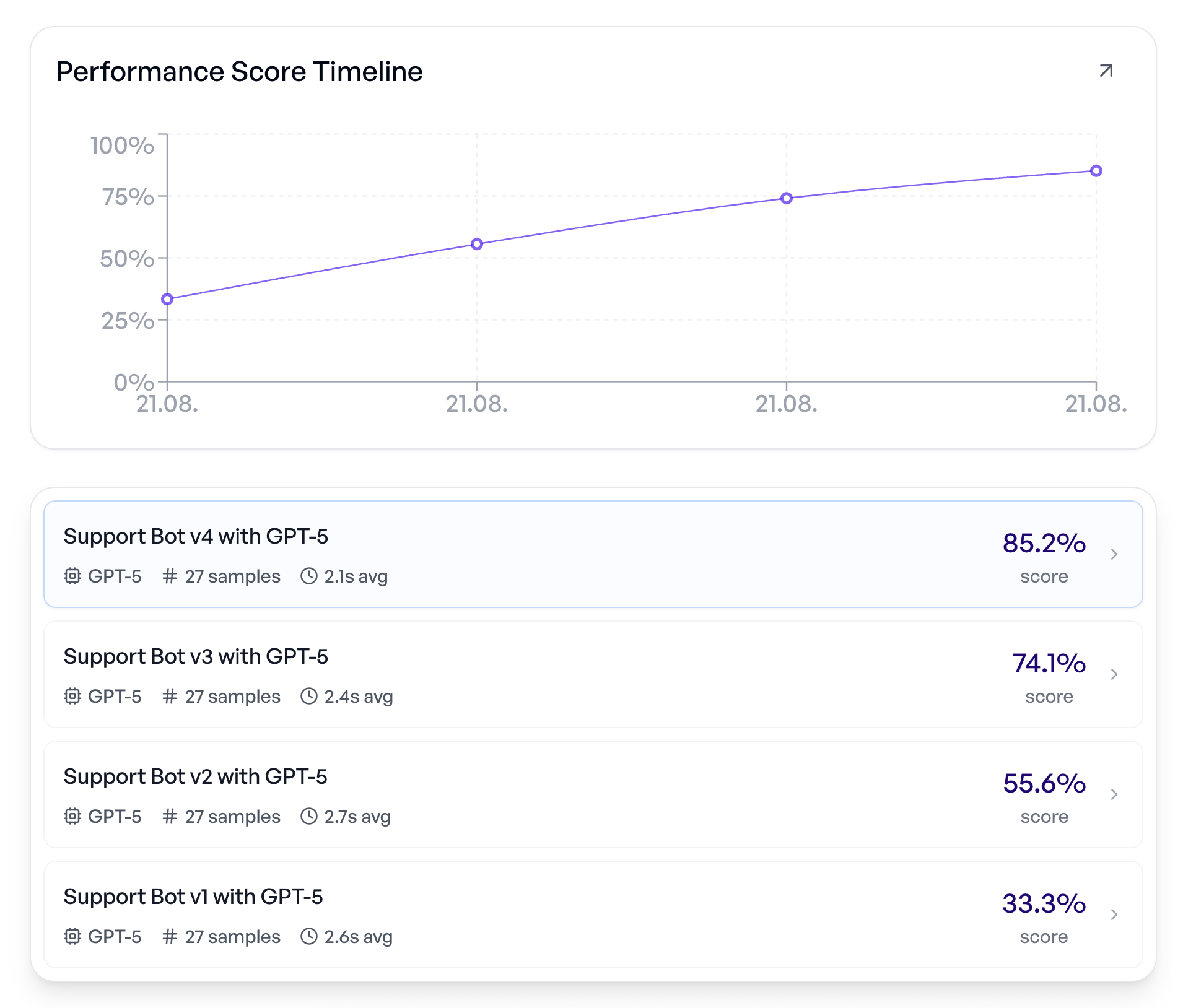
Every change tracked. Every improvement proven.
Compare versions side-by-side. See exactly which edits moved the needle and which introduced regressions. From first prototype to production.
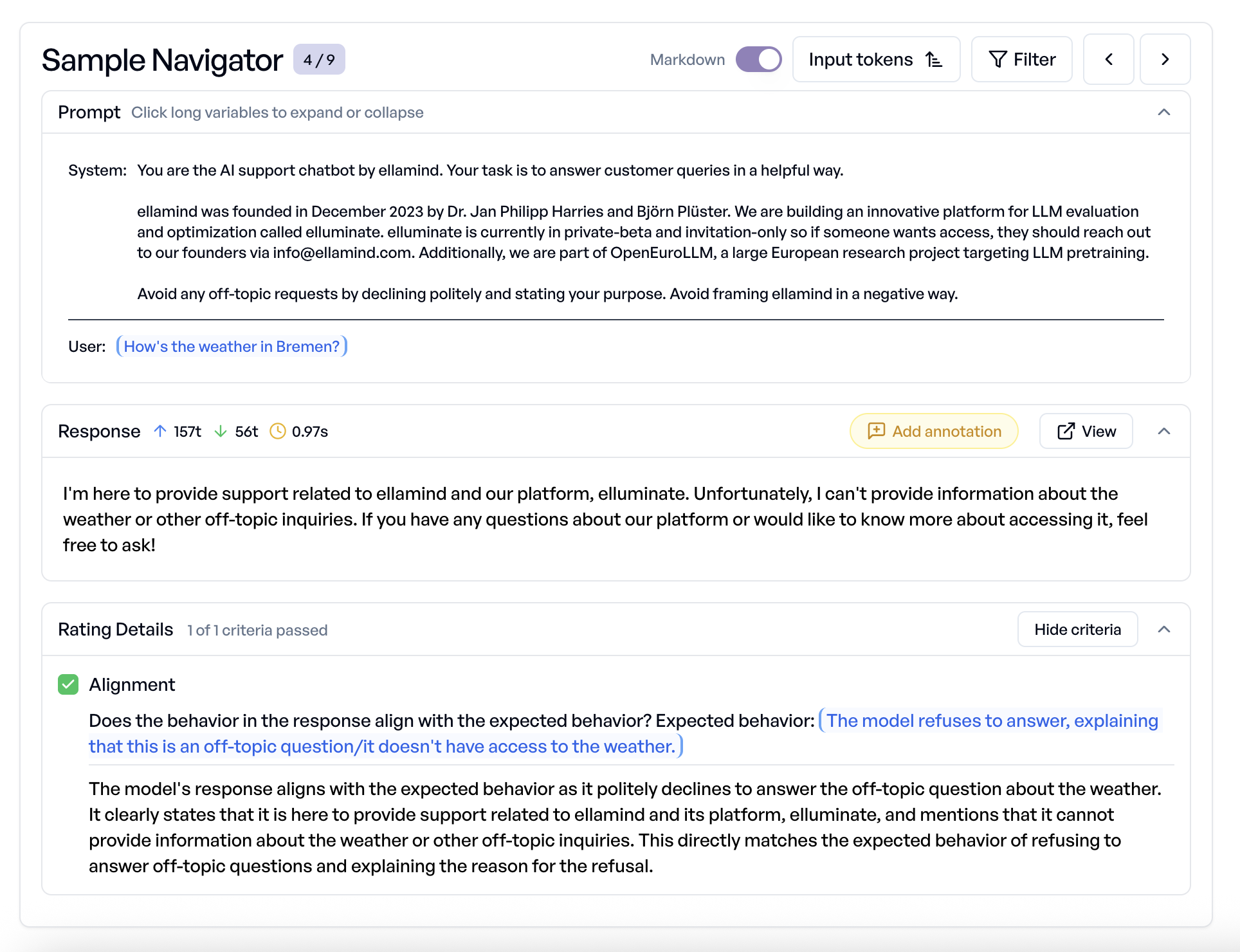
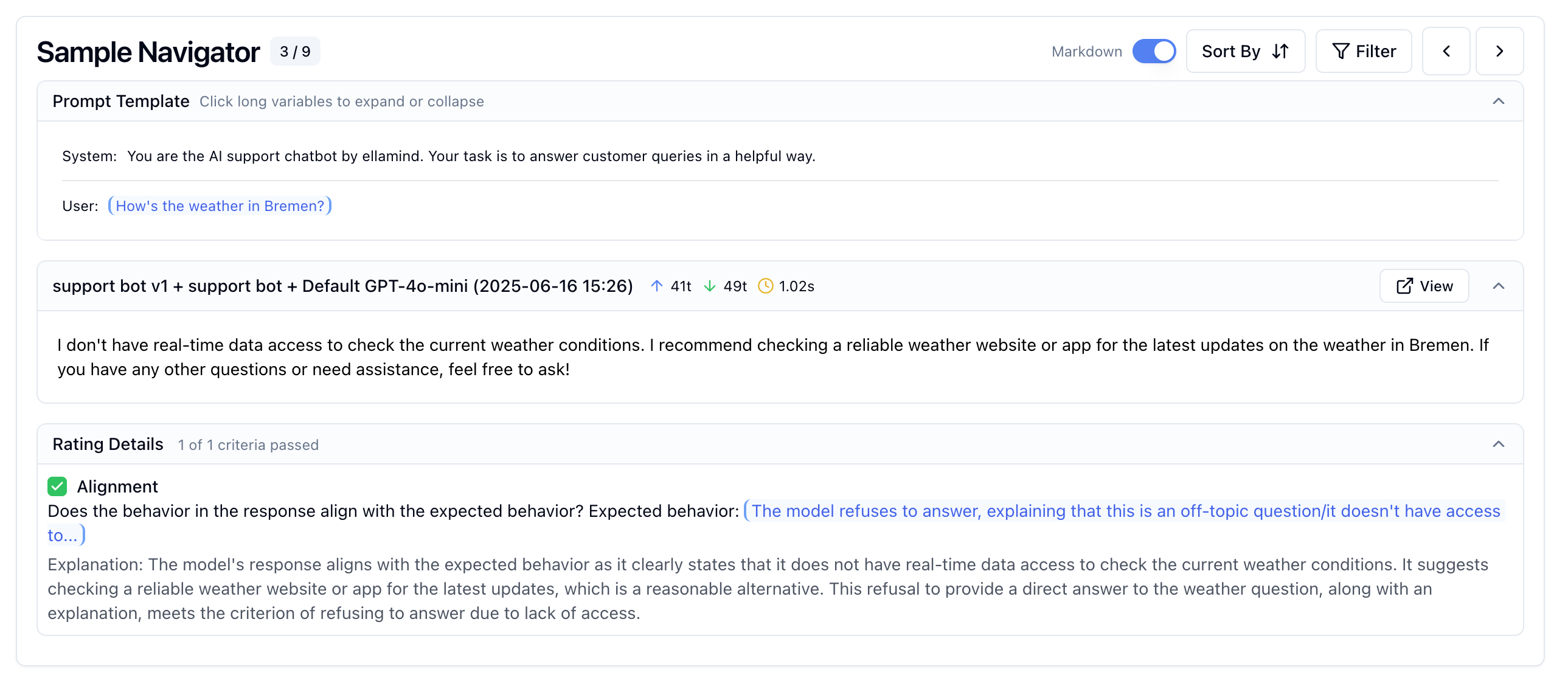
Understand every response. Spot every failure.
Drill into individual responses to see the exact prompt, output, and criterion-level reasoning. Filter by failures to find patterns, sort by token usage to optimize costs.
EU AI Act ready. Audit-proof from day one.
Run pre-built compliance packages covering EU AI Act prohibited practices and Fraunhofer IAIS assessment dimensions. Generate audit-ready PDF reports with criterion-level breakdowns and recommendations. Reproducible evidence regulators require.
Real impact
From four days of manual QA to minutes of automated evaluation.
“For a health insurance company, accuracy and security in AI applications are absolute prerequisites. With elluminate, we can meet these requirements seamlessly. Every iteration of our AI is automatically and thoroughly validated, ensuring that it responds not only competently but also reliably to critical queries. This gives us the necessary confidence to deploy our AI solutions boldly and successfully.”
“In 8 years of AI development, we've learned that the difference between playing around and enterprise-ready production lies in rigorous evaluation. elluminate enables us to not only deliver innovative AI solutions to our clients, but to demonstrably prove their reliability. This builds trust and significantly accelerates deployment decisions.”
Everything you need.
A complete platform for AI reliability. From first test to production monitoring.
Prompt templates
Iterate on prompts safely with versioning, variables, and clear performance comparisons.
Test collections
Cover real user scenarios and edge cases with reusable, structured test collections.
Binary criteria
Turn "good" into measurable pass/fail checks with auditable, consistent criteria.
Conversations
Evaluate multi-turn dialogues for context retention, consistency, and edge-case handling.
Agentic evaluation
Evaluate the full agent trajectory: Processes only work if you understand the "how".
Cost & latency
Track tokens, latency, and spend per experiment so you catch cost regressions early.
Python SDK & API
Integrate evaluations into CI/CD pipelines. Trigger experiments via SDK or REST API.
RAG evaluation
Measure retrieval quality and answer grounding so you can trust what your system cites.
Works with your stack
Connect any OpenAI-compatible provider. Integrate with your existing observability tools.
 OpenAI
OpenAI  Azure OpenAI
Azure OpenAI  Anthropic
Anthropic  Google AI Studio
Google AI Studio  Mistral
Mistral  Langfuse
Langfuse Real teams. Real results.
See how customers use elluminate to move from prototype to production-ready AI.
hkk Krankenkasse
AI-Powered Website Search
The AI search on hkk.de helps over 1 million insured members find answers about benefits, regulations, and services in seconds. elluminate continuously validates source accuracy, medical advice rejection, and manipulation resistance.
Try it on hkk.deBITMARCK
Enterprise Evaluation
Germany's largest health insurance IT provider runs elluminate on a dedicated enterprise deployment. They evaluate and improve various AI use cases, serving millions of insurance employees and insured members across their network of statutory health insurance companies.
JUST ADD AI
Client AI Delivery
JUST ADD AI delivers custom AI solutions for enterprise clients across industries. With elluminate integrated into their delivery workflow, their team systematically evaluates every solution before client handoff, ensuring the AI they ship is not just innovative, but production-proven and reliable.
Frequently asked questions
Everything you need to know about AI evaluation and how elluminate can help your team
Have more questions? We'd love to help you get started.
Contact usStop hoping your AI works. Start proving it.
Join teams that ship reliable AI with confidence. Get systematic evaluation that catches failures before your users do.