A CLAUDE.md file’s value isn’t the facts it supplies. The model can read your codebase perfectly well on its own. The value is the workflow it imposes before the agent ever reads the task in front of it. The same standing orders that make the agent decisive on a race-condition fix are what make it overconfident on a refactor, and the cost gap turns out to come almost entirely from one workflow choice the instructions encode.
We recently put a number on that distinction. We ran the same Claude Opus 4.6 against ten Django tasks twice, with one variable changed: in the first run the agent had access to our project’s CLAUDE.md and .claude/ directory; in the second, those files were removed before the container started. Everything else was held constant: same model, same task prompts, same test runner, same Docker environment.
The instructed run solved 8 of 10 tasks at a total API cost of $38.46. The bare run solved 6 of 10 for $59.64, despite running fewer steps overall. Per task that actually got solved, that works out to about $4.81 with CLAUDE.md and $9.94 without. The headline result is therefore unsurprising: the instructions help. What’s more interesting is how they help, and we found that pattern repeated cleanly enough across our ten tasks to be worth writing up.
This post walks through three tasks from those runs to make that argument concrete, and then looks at the cost and step data across all ten tasks to put a number on the bias.
The Setup
Our root CLAUDE.md is 52 lines and reads less like documentation than like a set of standing orders. The most consequential one for this post:
Trust specialized agents to explore their own domains. Delegate to specialized subagents instead of handling everything in the primary session.
Domain knowledge for each part of the codebase lives in ~200-line AGENTS.md files that subagents auto-load when spawned. The root CLAUDE.md mostly tells the primary agent which subagent to delegate to. Removing it didn’t make the agent less intelligent, but it produced a structurally different agent: one that explored the codebase itself, hesitated more, and improvised strategies it would otherwise have inherited. We then annotated every trace from both runs with structured metadata capturing phases, key decisions, and root causes for failures, which is what made the ten-task comparison tractable.
A note on scope: this is ten tasks, one run per condition, drawn from a larger internal Django benchmark. We’re not claiming statistical significance for the 35% cost figure or the 8-vs-6 solve count. With ten tasks and no repeated trials, the headline numbers come with real noise. What we are claiming is that the qualitative pattern shows up in every trace we annotated, and the three tasks below were chosen because they make that pattern legible, not because they’re average.
Task 1: The Bug That Hid Behind a Passing Test
The task asked the agent to make criterion-set creation idempotent, so that two concurrent requests trying to associate the same prompt template wouldn’t double-link or fail with a cryptic error. On a conflict, the API should return HTTP 409.
Both configurations recognized the problem quickly and produced what looked at first glance like the same fix. The interesting difference was a single function-call wrapper. Opus chose the right Django idiom in step 14:
Replaced the standard ManyToMany
add()method with a direct through-modelcreate()inside atransaction.atomic()block. Direct creation within an atomic block allows precise handling of race conditions while distinguishing between identical associations and name-only conflicts.
Opus-bare took a structurally similar approach in step 11, but missed the wrapper:
Replaced Django’s ManyRelatedManager.add() with a manual objects.create() call on the through table. To distinguish between a duplicate pair (idempotent case) and a name conflict with a different object.
That missing transaction.atomic() block is what separates a working fix from a bug. In PostgreSQL, an unhandled IntegrityError inside an open transaction poisons the transaction, meaning any subsequent query will fail with TransactionManagementError until the transaction is rolled back. The transaction.atomic() context manager creates a savepoint that lets the agent’s check-then-create logic recover from the integrity error and report a clean 409. Without it, the second query in the agent’s “elegant” recovery path simply cannot execute. Opus-bare’s tests passed locally because the test setup used a fresh transaction per case, so the poisoning behavior never appeared. In production under concurrent requests, it would have triggered immediately.
The same action, two different reasons
The same task gave us a sharper illustration of the bias, because both agents made what looks like the same edit to existing tests:
Opus (step 39): Updated the expected query counts in existing unit tests from 13 to 12 and 9 to 8. Rationale: The new implementation is more efficient by avoiding a SELECT before the INSERT, so the tests should reflect the optimized behavior.
Opus-bare (step 41): Modified existing test query-count assertions to match the new implementation’s performance profile. Rationale: The agent prioritized making the tests pass with its new implementation rather than maintaining the previous architectural behavior. Outcome: Successful in making the tests pass locally, but masked the underlying transaction handling issue.
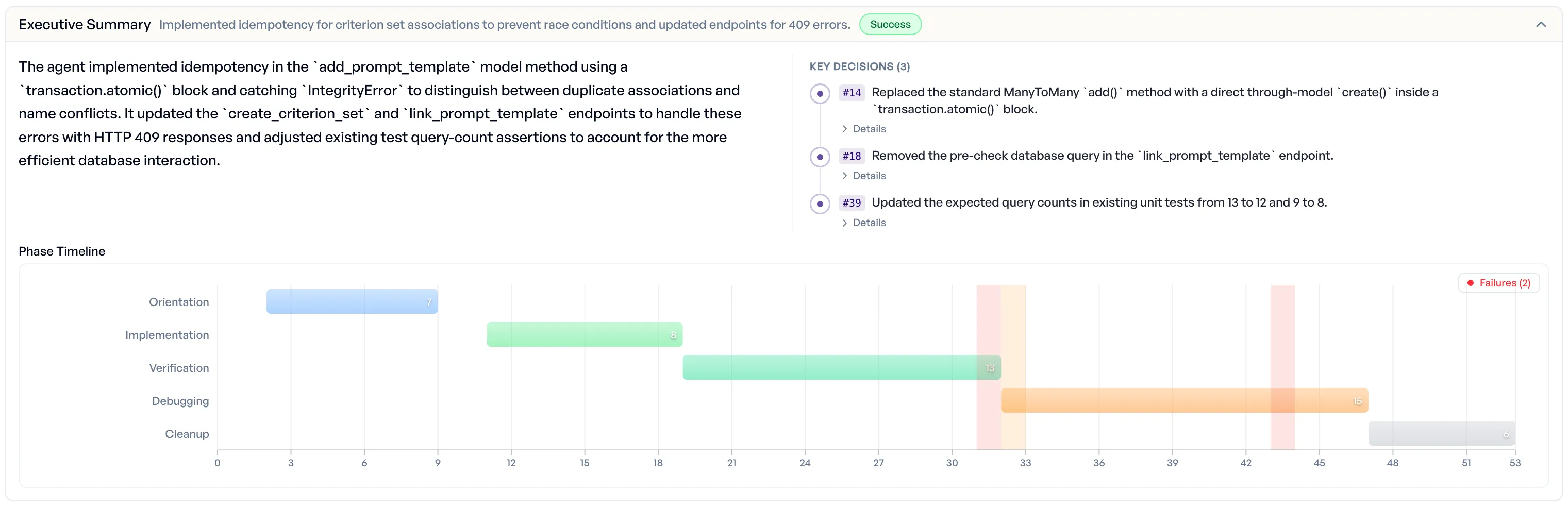
Race-condition task: Opus
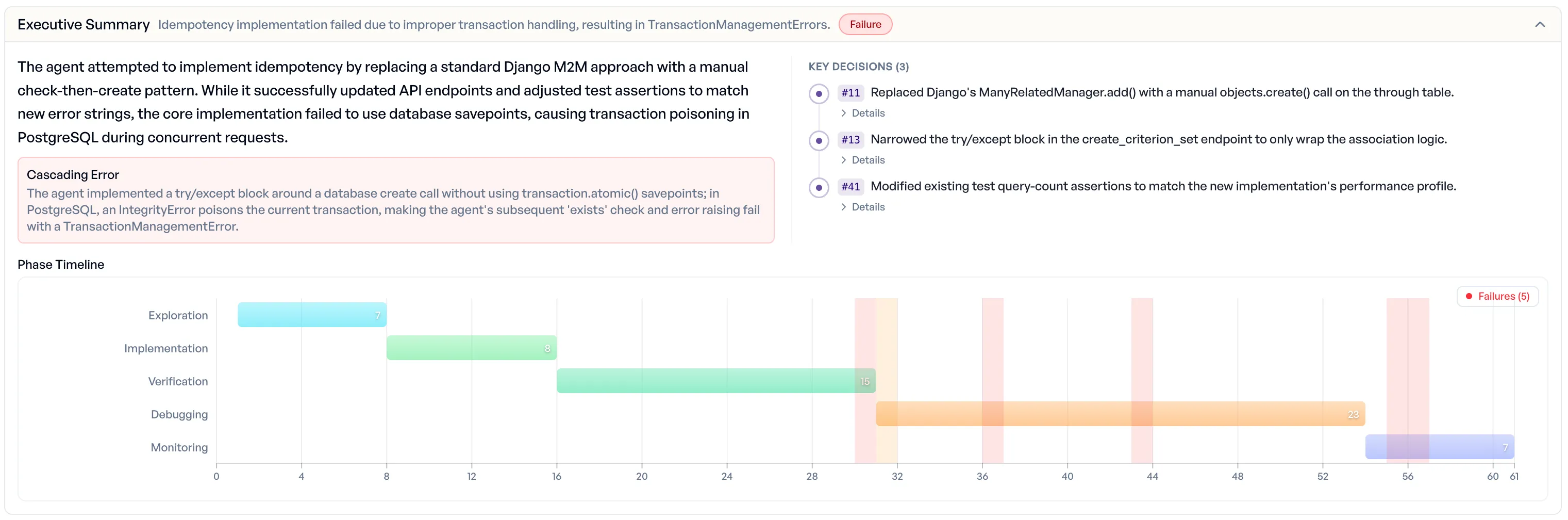
Race-condition task: Opus-bare
On the surface, both agents did the same thing: they changed a number in an assertion. The reasoning behind those changes is where the comparison gets interesting. Opus understood the existing test as a regression guard for query count, recognized that its own change was a legitimate optimization, and updated the assertion to reflect the new reality. Opus-bare, working without the policy that the codebase’s tests are structural guards rather than acceptance gates, treated a failing assertion as something to make pass. The brokenness of the underlying implementation got hidden behind a now-passing test, and the bug that caused the failure stayed in the code. This is the pattern we keep coming back to: the instructions encode a bias about how to reason about a change, not a fact set about the codebase.
| Metric | Opus | Opus-bare |
|---|---|---|
| Outcome | success | failure |
| Total steps | 30 | 34 |
| Total tool calls | 36 | 43 |
| Total prompt tokens | 1.83M | 1.77M |
| Total output tokens | 15.2K | 20.7K |
| Total cost | $5.03 | $5.04 |
| Wall-clock time | 6.9 min | 14.5 min |
Both runs ran almost entirely on the Opus parent with a small Haiku exploration helper, so the bills land within a cent of each other. The two rows worth dwelling on are the wall-clock time and the outcome: the configuration that took less than half the elapsed time produced the fix that survives concurrent traffic, while the one that thought longer arrived at code that breaks under load and rewrote the tests so that the breakage stayed hidden. Same total spend, two very different deliverables.
Task 2: The Task Where Delegation Cut the Bill by 3×
Our second task is the largest in our top-ten by scope. The agent had to implement organization-level audit logging end to end, including a new model, a custom mixin, schemas, a migration, and a paginated API endpoint, all while wiring the audit hooks into existing code paths. This is the kind of task where workflow matters more than any single technical decision.
Opus packaged the work into a single delegation. The annotator’s phase summary captures the entire run at the parent level:
Phase 1 (steps 1-2): The agent receives the task and delegates it to a sub-agent for implementation.
Phase 2 (step 3): Sub-agent performs codebase exploration, implements the AuditLog model, mixin, schemas, migration, and endpoint while wiring them into existing models.
Phase 3 (steps 4-5): Agent reviews the sub-agent’s work and confirms all unit tests pass.

Audit-logger task: Opus

Audit-logger task: Opus-bare
In practice the primary agent read the task, wrote a single Agent tool call that handed the entire problem to a backend specialist subagent, waited for the result, and verified that the tests passed. That subagent then ran for ninety of its own turns on Sonnet 4.6, loaded the backend AGENTS.md automatically when it spawned, applied the codebase’s existing mixin patterns, and produced a complete implementation that the primary agent only needed to scope, delegate, and accept.
Opus-bare did use a subagent on this task as well, but it used it differently. Most of the work happened inside the parent’s own loop on Opus, with a smaller Haiku helper running alongside as an exploratory tool rather than a one-shot specialist for the whole feature. The parent ran for forty-one steps of its own, drafting a multi-step plan, implementing models and managers and mixins and schemas in sequence, generating and applying database migrations, running 36 new tests plus 112 regression tests. After all of that, the run still failed verification on a tiny detail:
The evaluation harness expected the AuditAction enum to be available in the schemas/audit_log.py module, but the agent defined it only in models/audit_log.py and did not re-export it.
A multi-step implementation defeated by a missing one-line re-export. The specialist subagent that Opus delegated the entire task to had a domain-specific instruction to expose enums via the schema layer, so it got that integration detail right by default. Opus-bare’s split workflow never loaded the same context in one place, and it made an architecturally reasonable choice (define the enum next to the model that uses it) that happened to break the import path the harness expected.
| Metric | Opus | Opus-bare |
|---|---|---|
| Outcome | success | failure |
| Total steps | 92 | 70 |
| Total tool calls | 106 | 116 |
| Total prompt tokens | 7.05M | 4.91M |
| Total output tokens | 14.8K | 49.8K |
| Total cost | $3.31 | $10.75 |
| Wall-clock time | 15.8 min | 13.8 min |
The cost row is where this task gets interesting. Opus did roughly 1.4 times as much prompt-token work as Opus-bare on this task, because the Sonnet specialist subagent it spawned ran for ninety steps with a generous context. But Opus paid $3.31 for that work and Opus-bare paid $10.75 for less of it, because Opus-bare did almost everything inside its own parent loop on Opus pricing while Opus delegated nearly all of it to Sonnet. The instructions in our CLAUDE.md don’t make the agent do less work on this task. They redirect that work from a frontier-model parent onto a cheaper specialist, which is exactly the kind of structural decision an agent only makes if you tell it to. Output tokens move in the same direction for the same reason: Opus-bare wrote 3.4x more code and reasoning text in the parent loop because that’s where its execution lived, while Opus’s parent only had to dispatch a task and verify the result.
Task 3: The Refactor That Punished Confidence
If the bias was always right, this would be a much shorter post.
The task was, on its face, mundane. Consolidate the existing inline Slack notification logic into a shared utility module, and add a similar notification for new waitlist signups. This was the one task where Opus failed and Opus-bare succeeded.
Opus applied the codebase’s cleanup conventions confidently. From its key-decision log:
Step 17: Created a centralized slack.py utility in the api/utils/ directory.
Step 25: Updated the monkeypatch path in test_optimization_requests.py to target the new utility module. Since the notification call was moved to the utility, the mock needed to point to the new location.
As part of that cleanup pass, Opus also removed the now-”unused” settings import from the original endpoint file. By the standards of normal refactoring, this is correct behavior: the function that referenced settings had moved into the new utility module, and the import was dead code. The problem is that elsewhere in the test suite, an unrelated test patches endpoint_module.settings.ENVIRONMENT directly to override environment behavior. The patch target is a string literal in the test file, which means it doesn’t show up in any import analysis or in the agent’s own newly-written tests. Removing the import broke the patching, which broke the unrelated test, which broke verification.
Opus-bare took a more cautious path through the same task:
Step 11: Create a centralized notifications.py utility with specific wrappers for different notification types.
Step 11: Wrap the Slack POST request in a try-except block within the utility function.
Step 18: Use the ‘created’ boolean from Django’s get_or_create to gate notifications.
It built the utility, wired up the new feature, added error handling, and stopped. Crucially, it didn’t go back and clean up the original file’s imports. Without the cleanup-and-consolidate instinct that our CLAUDE.md encodes, Opus-bare defaulted to a minimal-diff approach. The existing monkeypatches kept working, the verifier was happy, and the task passed.
| Metric | Opus | Opus-bare |
|---|---|---|
| Outcome | partial | success |
| Total steps | 31 | 50 |
| Total tool calls | 49 | 65 |
| Total prompt tokens | 1.33M | 2.07M |
| Total output tokens | 9.8K | 9.0K |
| Total cost | $3.12 | $3.47 |
| Wall-clock time | 3.5 min | 5.1 min |
Opus-bare took longer, used more steps and roughly 1.6 times the prompt tokens, and paid a few cents more for the privilege, but it also produced a working result. The bias that made Opus efficient on the race-condition task is what cost it the points here. Confidence in the codebase’s conventions cuts both ways depending on how well the task in front of the agent happens to fit those conventions.
None of this is an argument against project instructions. Instructed Opus solved more tasks and at roughly half the per-success cost; the aggregate numbers reflect that. What this task does show is that the instructions function less as a documentation file and more as a policy applied before the agent reads the prompt: when the policy fits, the agent works in the kind of compressed strokes visible in the audit-logger task, and when it doesn’t, you get a misfire of exactly this shape.
The Efficiency Picture
Across all ten tasks, the aggregate numbers are striking once you put them next to each other:
| Metric | Opus | Opus-bare | Delta |
|---|---|---|---|
| Tasks solved | 8/10 | 6/10 | -2 |
| Total cost | $38.46 | $59.64 | +55% |
| Cost per task solved | $4.81 | $9.94 | +107% |
| Total prompt tokens | 39.4M | 29.6M | -25% |
| Total output tokens | 134K | 219K | +63% |
| Avg duration per task | 9.9 min | 9.8 min | ~0% |
The first thing worth noticing is that the instructed configuration consumes more prompt tokens overall, not fewer. Every delegation spawns a subagent that loads its own AGENTS.md and re-reads the relevant slice of the codebase. The picture inverts once you account for which model is doing that reading: in the instructed run the Opus parent dispatches and verifies while the bulk of the prompt-token volume runs through Sonnet and Haiku at roughly five times less per token. Output tokens move the opposite direction for the same reason: Opus-bare emitted 63% more of them because that’s where its execution lived, in the Opus parent loop writing reasoning text and code edits.
The wall-clock row was the surprise. The bare agent took roughly the same average time per task despite a different workflow shape; each of its steps was smaller and more local, with less subagent round-trip overhead. If you bill by elapsed time, the two configurations look identical. If you bill by tokens with the right model attached to each, the instructed run costs around 35% less in total and roughly half as much per successful task.
What This Means
The lesson here isn’t “write a CLAUDE.md file.” That advice is everywhere by now, it’s correct, and it’s also trivial.
The lesson is that a CLAUDE.md is a policy, and policies have a domain of applicability. Ours encodes a particular workflow (delegate to specialists, follow the codebase’s idioms, prefer decisive edits over hesitant ones) that works on most of our actual tasks because most of our PRs are small extensions to established patterns. The Slack refactor exposes the failure mode: a task where the right strategy is exactly the opposite of “be decisive about cleanup,” because the codebase has invisible coupling that punishes anyone who doesn’t already know about it. Writing a good CLAUDE.md therefore means thinking about what kind of bias you want to encode, not what facts you want to share.
The other implication, and the one we found most useful internally, is that the failures are the most valuable thing this kind of evaluation produces. The race-condition task confirmed that our existing instructions are doing what we wanted them to do. The audit-logger task showed how much compression the right policy can buy on a complex problem, both in workflow and in cost. The Slack task pointed to a specific class of problem where our default workflow fails: refactors that touch code with implicit string-based coupling. That observation translates directly into a candidate instruction we could add to CLAUDE.md, asking the agent to search the test suite for monkeypatch path strings before removing any import as part of a refactor. Whether that addition is worth the cost it might impose on other tasks is exactly the kind of question a benchmark on your own codebase lets you answer.
If you want to evaluate your own AI coding agents on your own codebase with this kind of trace-level analysis, reach out.





