At a mid-size organization, AI Act compliance usually belongs to one person — the KI-Zuständige, often doing it alongside another full-time job. They open Annex IV of the EU AI Act for the first time and find nine sections: system design, data, performance, risk management, post-market monitoring, and the rest. There is no template. No worked example. No colleague down the hall who has done this before.
The Act is unambiguous that the documentation is mandatory. It is almost silent on how to produce it. The harmonized standards meant to fill that gap (CEN/CENELEC JTC 21) are delayed to roughly Q4 2026. Meanwhile Germany’s market-surveillance authority, the BNetzA, has signaled it will review technical documentation first, which is the exact artifact nobody has a method for. So the work lands on one desk, and the honest state of the art is that nobody quite knows how to do this yet.
Why it’s hard
The difficulty isn’t typing effort. It’s structural, in three ways.
The form assumes you trained the model. Half of Annex IV asks about training datasets, model architecture, and training procedures, none of which are yours if you built on a model from someone else. Working out whether you’re the deployer or the provider in the first place is its own trap — the subject of a companion post, you became the provider.
It’s slow, and front-loaded. We don’t have clean numbers on this yet, but everything we see points the same way: a first pass on a single system runs into weeks, not days — nine sections, no template, the knowledge scattered across legal, product, and engineering. The cost only comes down on the second pass, and the lone compliance owner (several systems, no team, no template) never gets there; every system stays a slow first pass.
The alternatives are bad. External consultants are expensive and don’t scale when the system changes next quarter. The other option is to wait, which stops working once enforcement powers land in August.
What we built
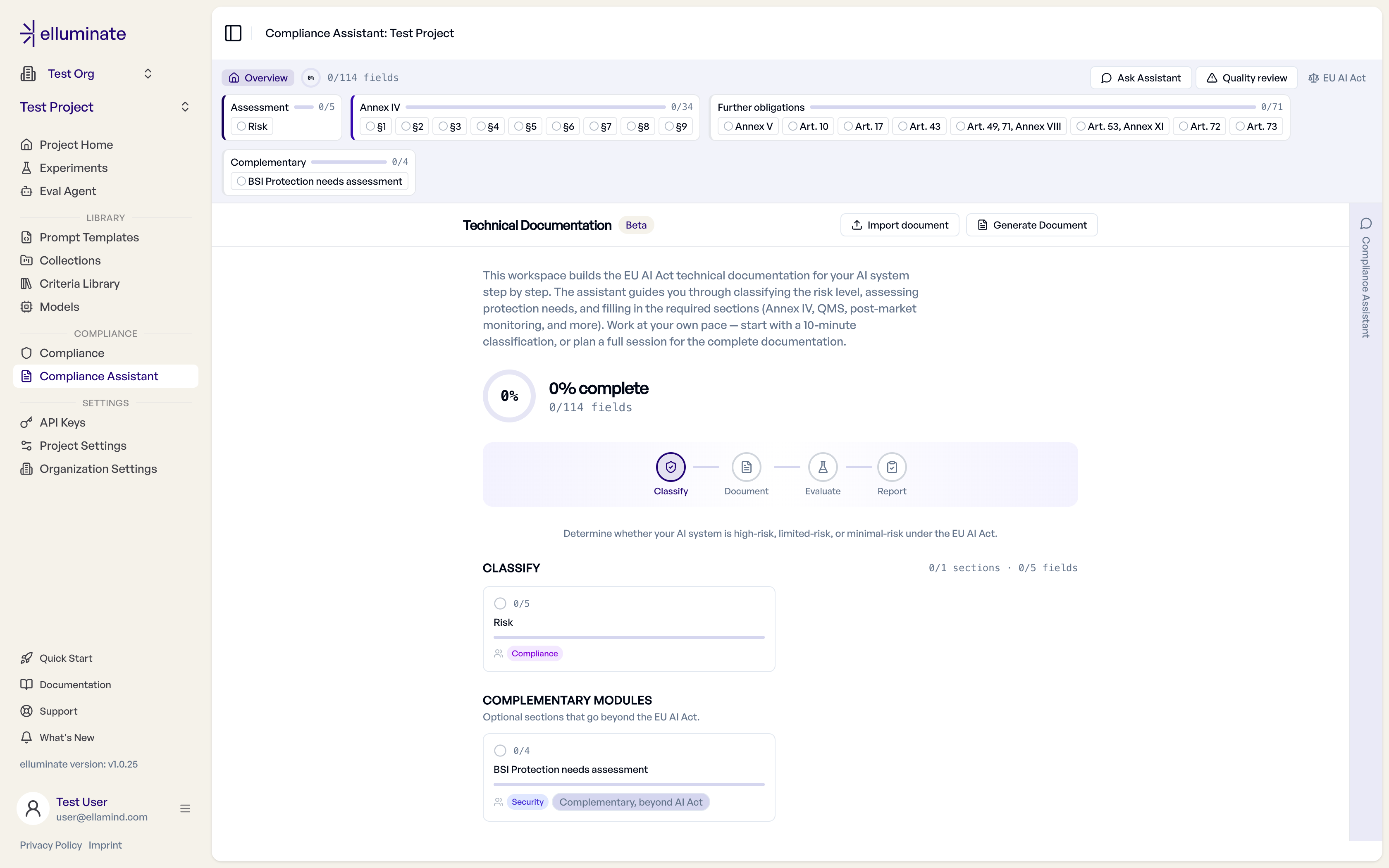
This gap is what the Compliance Documentation Assistant is for. It’s a module inside elluminate, and from today it’s available in beta to all elluminate customers. It turns the blank-form problem into a guided workflow in four steps:
- Classify. Determine the risk level, clarify your role (deployer or provider), and scope which documentation you actually owe. About ten minutes, with the legal basis shown for every call.
- Document. Work through the sections one at a time, with the exact legal citation visible for each field. The assistant proposes; you confirm.
- Evaluate. Bring your own use-case-specific evaluation results from elluminate into the sections that make claims, so the documentation rests on evidence rather than assertion.
- Report. Generate a draft document at any stage, with unfinished sections flagged as open gaps.

The part that isn’t a checklist
What separates this from a smarter form is that it connects the documentation to evidence.
Compliance documentation is usually self-declaration: you assert that the system performs accurately, and a reviewer takes your word for it. Because the Assistant lives on the same platform as your evaluations, you can back a claim with your own use-case-specific results — the evidence that’s actually relevant to your system, not a generic checklist. If Section 4 says the model performs accurately, the evaluation behind that claim lives on the same platform, not in a separate tool.
This is the part that’s hard to copy. GRC platforms manage the compliance process but can’t test an AI system. Evaluation tools test the system but produce no regulatory documentation. The Assistant does both, because elluminate was already the evaluation half.
Built for people who don’t trust black boxes
Compliance officers are risk-averse by profession, and they’re right to be. So the Assistant is built to be checked at every step:
- Every classification shows its reasoning chain.
- Documentation fields reference the exact legal provision in the original text.
- Gaps are marked, never hidden.
- A human confirms at every decision gate.
It prepares documentation for a human to review and submit; it never claims to certify that you comply.
A compliance lead at a German statutory health insurer summed up the first session in three words: “Spart so viel Arbeit” — it saves so much work. Their actual feature request was the tell. Not “make it do more,” but “give me longer justifications I can defend in an audit.” That’s the bar we’re building to.
Why we’re calling it beta
Because it is one.
Today the product covers the AI Act itself. Other regimes (DSGVO, BaFin and BSI guidance) come later. A few pieces, document import and the full evaluation-evidence integration, are still landing. And the “hours instead of weeks” time saving we keep hearing about is still anecdotal; we haven’t measured it across customers yet. The beta is how we measure it. Your feedback decides what we build next.
Try it
If you run AI in a regulated context in the EU, the documentation is coming for you whether or not the standards have caught up. The Assistant is live for elluminate customers now. Turn it on and run a classification on a real system; ten minutes is enough to tell whether it’s useful. If you’re not on elluminate yet, talk to us.
And if you want the thinking underneath it, a companion post digs into why you may already count as the provider of your AI system, and we’ve written separately on how to tell whether your chatbot is too cautious or too confident.





